Hadoop实验4:MapReduce编程
1 实验原理
1.1 MapReduce组成原理
最简单的MapReduce应用程序至少包含 3 个部分:一个 Map 函数、一个 Reduce 函数和一个 main 函数。在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。main 函数将作业控制和文件输入/输出结合起来。
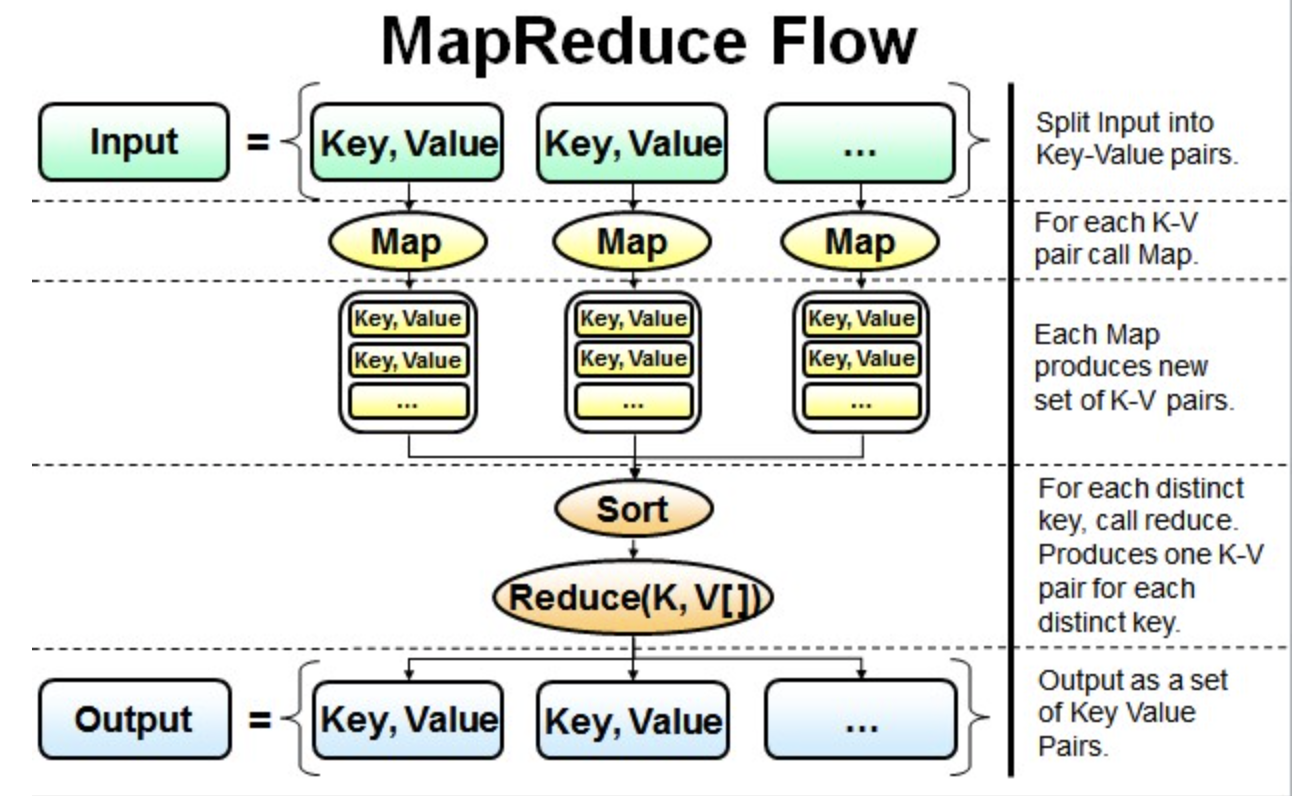
并行读取文本中的内容,然后进行MapReduce操作。
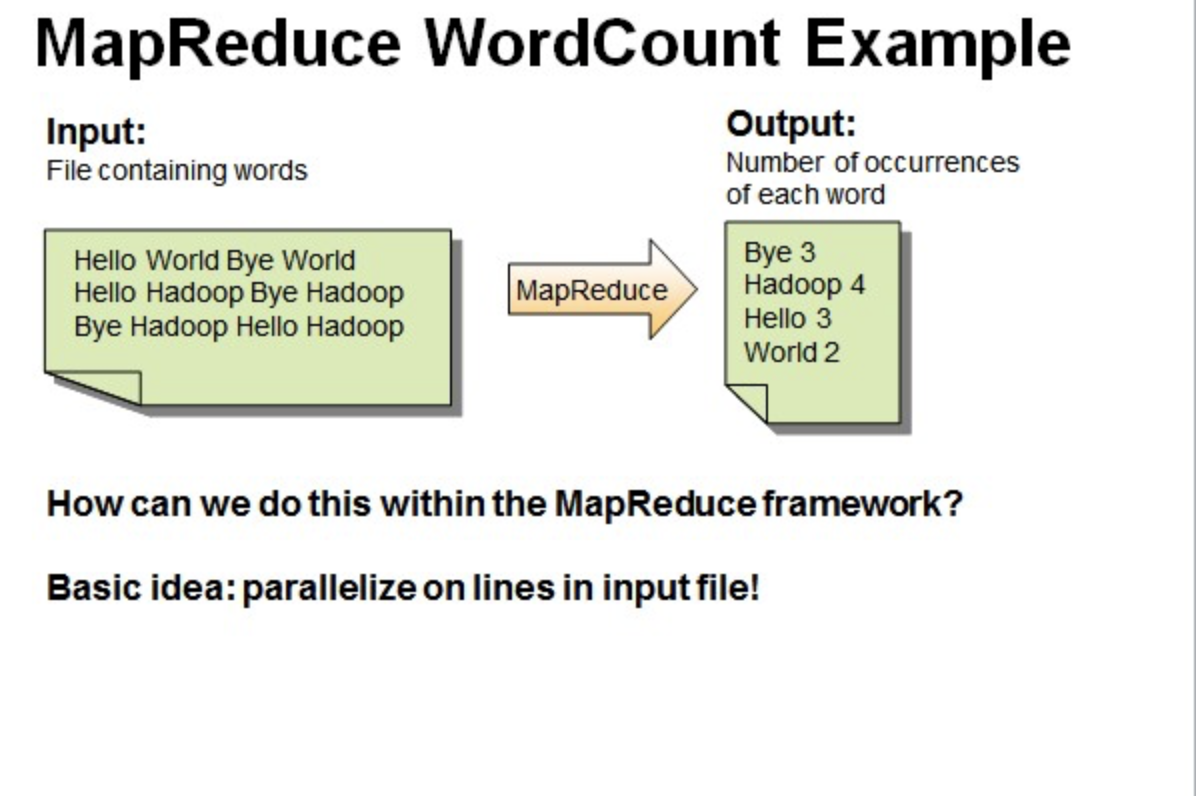
一个有三行文本的文件进行MapReduce操作。
读取第一行Hello World Bye World ,分割单词形成Map。
<Hello,1> <World,1> <Bye,1> <World,1>
读取第二行Hello Hadoop Bye Hadoop,分割单词形成Map。
<Hello,1> <Hadoop,1> <Bye,1> <Hadoop,1>
读取第三行Bye Hadoop Hello Hadoop,分割单词形成Map。
<Bye,1> <Hadoop,1> <Hello,1> <Hadoop,1>
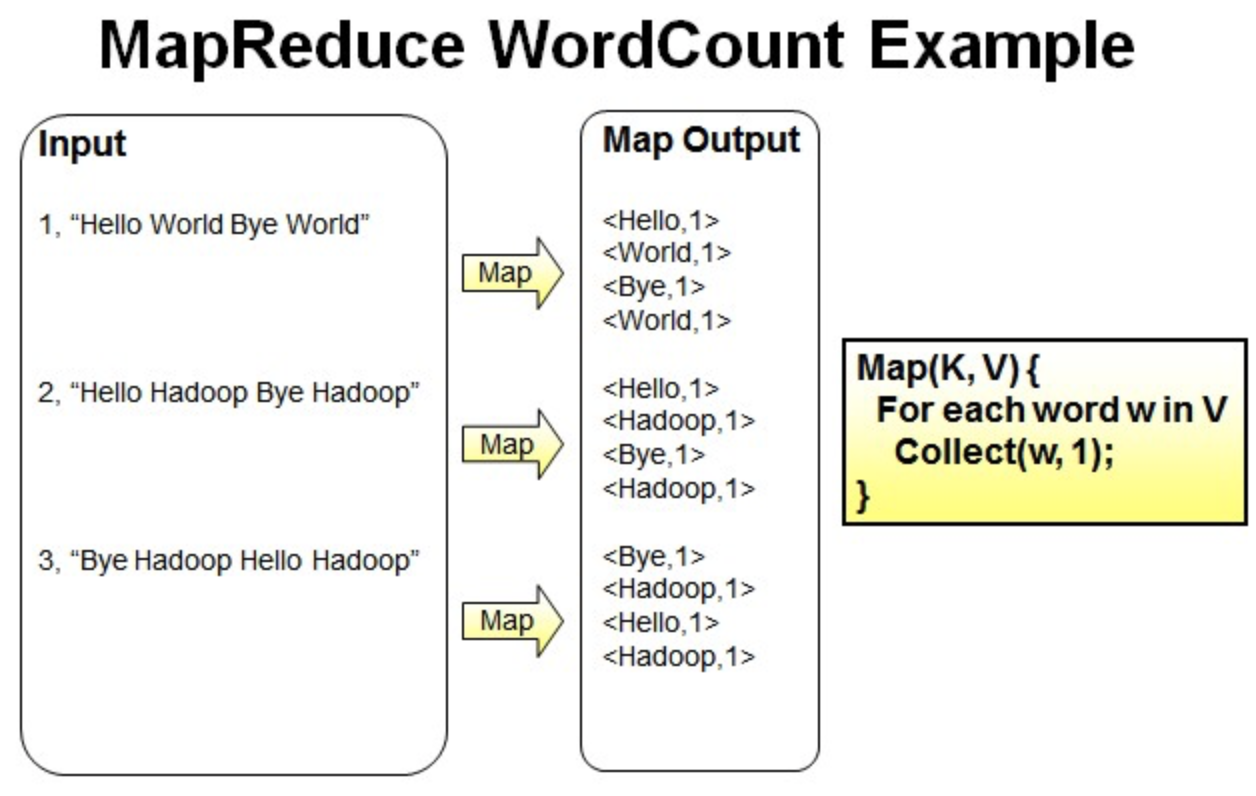
Reduce操作是对map的结果进行排序,合并,最后得出词频。
经过进一步处理(combiner),将形成的Map根据相同的key组合成value数组。
<Bye,1,1,1> <Hadoop,1,1,1,1> <Hello,1,1,1> <World,1,1>
循环执行Reduce(K,V[]),分别统计每个单词出现的次数。
<Bye,3> <Hadoop,4> <Hello,3> <World,2>
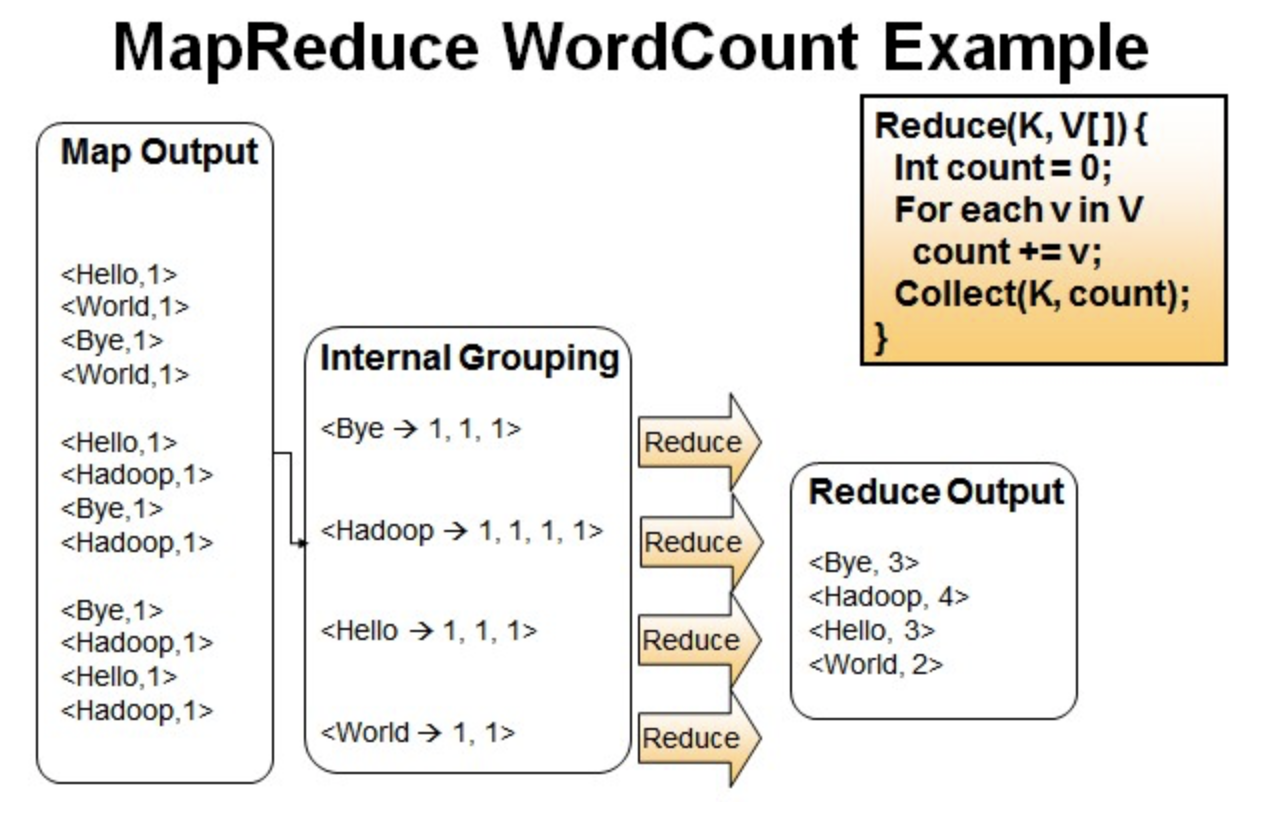
1.2 WrodCount处理过程
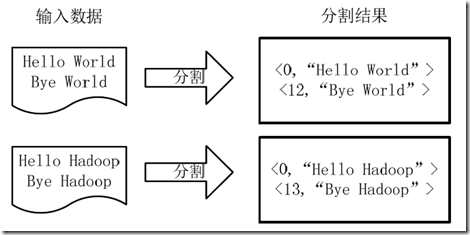
1.将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成<key,value>对,如下图所示。这一步由MapReduce框架自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows和Linux环境会不同)。
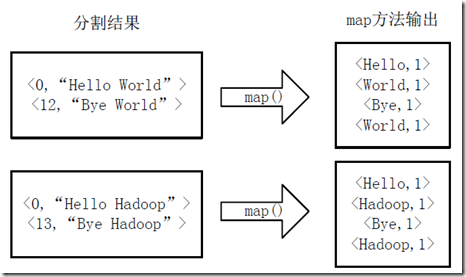
2.将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如下图所示。
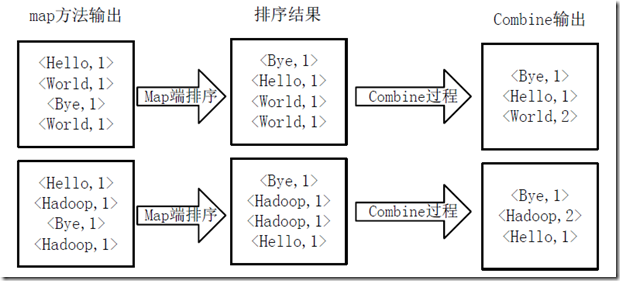
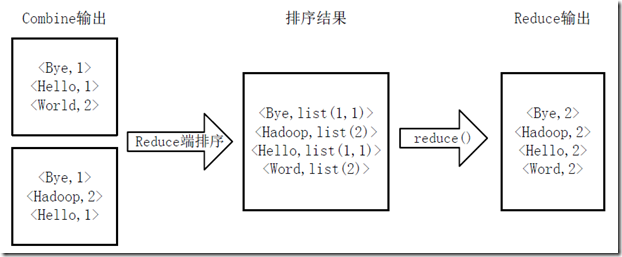
3.得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果,如下图所示。
4.Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,如下图所示。
2 实验准备
2.1 创建工作目录
本实验的工作目录为~/course/hadoop/mr_pro,使用以下命令创建和初始化工作目录:
1
2
mkdir -p ~/course/hadoop/mr_pro
cd ~/course/hadoop/mr_pro
2.2 启动Docker和Hadoop集群
首先按照顺序启动四个Docker容器
1
2
3
4
docker start master
docker start slave1
docker start slave2
docker start slave3
接着使用以下命令,进入到master环境内:
1
docker exec -it --privileged master /bin/bash
然后在master容器内启动Hadoop服务
1
2
3
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
2.3 打开eclipse并配置工作空间
在桌面右键打开终端输入如下命令打开eclipse:
1
eclipse &
打开eclipse后选择/headless/course/hadoop/mr_pro做为工作空间。
3 WordCount
3.1 新建项目
1.在eclipse中依次点击:File->New->Project->Map/Reduce Project->Next。
2.在项目名称(Project Name)处填入WordCount,将工程位置设置为文件夹/headless/course/hadoop/mr_pro/WordCount,点击Finish。
3.2 准备测试数据
新建终端,使用如下命令新建一个文本文件:
1
2
3
4
5
6
cd ~/course/hadoop/mr_pro/WordCount/
mkdir target
mkdir data
cd data
echo "Hello World" >> file1.txt
echo "Hello MapReduce" >> file2.txt
使用如下命令进入master节点:
1
docker exec -it --privileged master /bin/bash
主机的~/course目录挂载到了master节点的/course目录。
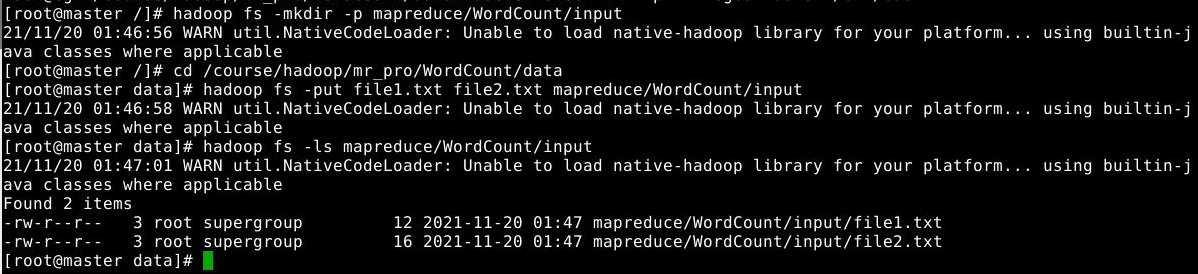
在master节点中使用如下命令新建目录,并将文本文件上传到目录:
1
2
3
4
hadoop fs -mkdir -p mapreduce/WordCount/input
cd /course/hadoop/mr_pro/WordCount/data
hadoop fs -put file1.txt file2.txt mapreduce/WordCount/input
hadoop fs -ls mapreduce/WordCount/input
3.3 添加 MapReduce 编程框架
MapReduce 编程框架分为三个部分,请在 Eclipse 中的 WordCount 下分别创建如下三个类:
WcMap、WcReducer、WcRunner
接着在类中编写代码。
3.4 Map过程
Map过程需要继承org.apache.hadoop.mapreduce包中Mapper类,并重写其map方法。通过在map方法中添加两句把key值和value值输出到控制台的代码,可以发现map方法中value值存储的是文本文件中的一行(以回车符为行结束标记),而key值为该行的首字母相对于文本文件的首地址的偏移量。然后StringTokenizer类将每一行拆分成为一个个的单词,并将<word,1>作为map方法的结果输出,其余的工作都交有MapReduce框架处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WcMap extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String str = value.toString();
String[] words = StringUtils.split(str," ");
for (String word:words) {
context.write(new Text(word), new LongWritable(1));
}
}
}
3.5 Reduce过程
Reduce过程需要继承org.apache.hadoop.mapreduce包中Reducer类,并重写其reduce方法。Map过程输出<key,values>中key为单个单词,而values是对应单词的计数值所组成的列表,Map的输出就是Reduce的输入,所以reduce方法只要遍历values并求和,即可得到某个单词的总次数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WcReduce extends Reducer<Text, LongWritable, Text, LongWritable> {
public void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
long count = 0;
for(LongWritable value:values) {
count += value.get();
}
context.write(key, new LongWritable(count));
}
}
3.6 执行MapReduce任务
在MapReduce中,由Job对象负责管理和运行一个计算任务,并通过Job的一些方法对任务的参数进行相关的设置。此处设置了使用TokenizerMapper完成Map过程中的处理和使用IntSumReducer完成Combine和Reduce过程中的处理。还设置了Map过程和Reduce过程的输出类型:key的类型为Text,value的类型为IntWritable。任务的输出和输入路径则由命令行参数指定,并由FileInputFormat和FileOutputFormat分别设定。完成相应任务的参数设定后,即可调用job.waitForCompletion()方法执行任务。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WcRunner {
public static void main(String[] args)
throws IOException,ClassNotFoundException,InterruptedException
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WcRunner.class);
job.setMapperClass(WcMap.class);
job.setReducerClass(WcReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
3.7 实验结果
将项目导出为WordCount.jar 到本实验工作目录的WordCount/target子目录下,进入master节点,切换到 jar 包所在目录/course/hadoop/mr_pro/WordCount/target,输入以下命令提交作业到集群运行:
1
hadoop jar WordCount.jar mapreduce/WordCount/input mapreduce/WordCount/output
运行结果如下:

4 祖孙辈关系
4.1 新建项目
在本实验工作目录下创建文件夹Relation。
在eclipse中依次点击:File->New->Project->Map/Reduce Project->Next。
在项目名称(Project Name)处填入“Relation”,将工程位置设置为上述的文件夹,点击“Finish”。
下载log4j配置文件:log4j.properties.txt
然后将该文件上传至实验环境内的“Relation”项目的src目录下,并将文件重命名为log4j.properties。
4.2 准备relation.dat
在eclipse的Relation目录上,单击右键->New->Folder,填入data,创建数据目录。
在data目录上,单击右键->New->File,填入relation.dat,创建数据文件,数据文件内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Tom Lucy
Tom Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesse
Philip Terry
Philip Alma
Mark Terry
Mark Alma
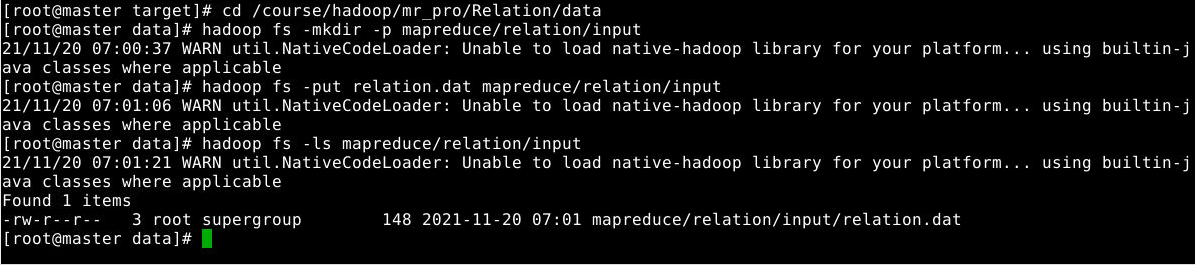
接着,在HDFS创建目录,将数据上传到该目录,
在master节点上执行的命令如下:
1
2
3
4
cd /course/hadoop/mr_pro/Relation/data #进入数据目录
hadoop fs -mkdir -p mapreduce/relation/input #在HDFS上创建目录
hadoop fs -put relation.dat mapreduce/relation/input #上传数据到HDFS
hadoop fs -ls mapreduce/relation/input #查看数据
4.3 添加 MapReduce 编程框架
MapReduce 编程框架分为三个部分,请在 Eclipse 中的 Relation 下分别创建如下三个类:
MyMapper、MyReduce、MyRunner
接着在类中编写代码。
4.4 Map过程
在src上,单击右键->New->Class->Name处填MyMapper->Finish,MyMapper的完整代码与解析如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String child = value.toString().split(" ")[0];
String parent = value.toString().split(" ")[1];
context.write(new Text(child), new Text("-" + parent));
context.write(new Text(parent), new Text("+" + child));
}
}
4.5 Reduce过程
在src上,单击右键->New->Class->Name处填MyReducer->Finish,MyReducer的完整代码与解析如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import java.io.IOException;
import java.util.ArrayList;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
ArrayList<Text> grandparent = new ArrayList<Text>();
ArrayList<Text> grandchild = new ArrayList<Text>();
for (Text t : values) {
String s = t.toString();
if (s.startsWith("-")) {
grandparent.add(new Text(s.substring(1)));
} else {
grandchild.add(new Text(s.substring(1)));
}
}
for (int i = 0; i < grandchild.size(); i++) {
for (int j = 0; j < grandparent.size(); j++) {
context.write(new Text(grandchild.get(i) + " "), grandparent.get(j));
}
}
}
}
4.6 执行MapReduce任务
在src上,单击右键->New->Class->Name处填MyRunner->Finish,MyRunner的完整代码与解析如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(MyRunner.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
4.7 实验结果
在Relation目录下新建target目录,导出Relation项目的jar包,jar包命名为Relation.jar.
在master节点输入hadoop jar命令提交作业到hadoop集群运行:
1
2
cd /course/hadoop/mr_pro/Relation/target
hadoop jar Relation.jar mapreduce/relation/input mapreduce/relation/output
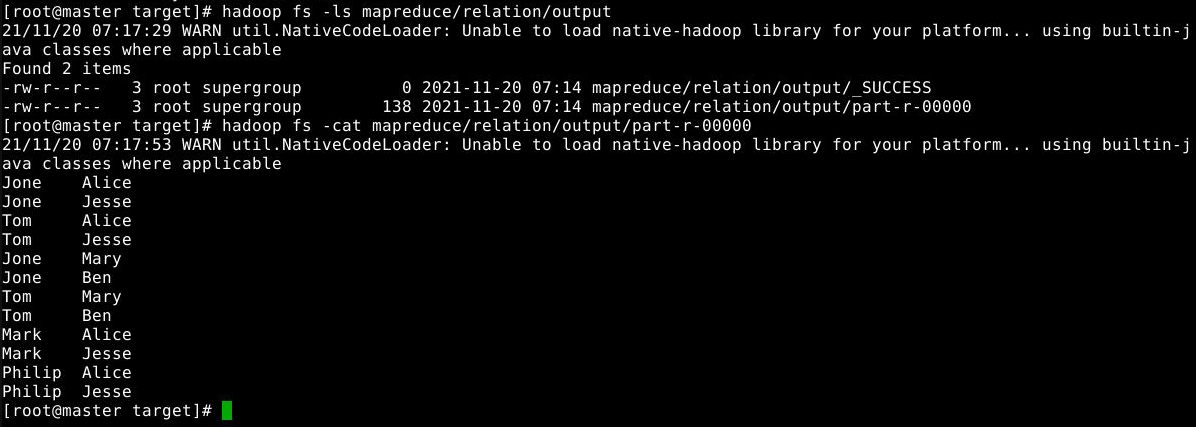
使用如下命令查看计算结果:
1
2
hadoop fs -ls mapreduce/relation/output
hadoop fs -cat mapreduce/relation/output/part-r-00000
5 索引倒排
5.1 新建项目
在本实验工作目录下创建文件夹Inverted。
在eclipse中依次点击:File->New->Project->Map/Reduce Project->Next。
在项目名称(Project Name)处填入Inverted,将工程位置设置为上述的文件夹,点击Finish。
5.2 准备 input.dat
在Inverted项目下分别创建data目录和target目录,从终端进入data目录,使用如下命令生成3个文本文件:1.txt,2.txt,3.txt
1
2
3
4
5
6
7
mkdir ~/course/hadoop/mr_pro/Inverted/data/
mkdir ~/course/hadoop/mr_pro/Inverted/target/
cd ~/course/hadoop/mr_pro/Inverted/data/
echo "MapReduce is simple" > 1.txt
echo "MapReduce is powerful and simple" > 2.txt
echo "Hello MapReduce bye MapReduce" > 3.txt
ls
在eclipse的Inverted项目目录上,即可在eclipse上显示新生成的三个文本文件。
在master节点上执行如下命令,在HDFS上创建目录,并将3个文件上传至HDFS上:
1
2
3
4
cd /course/hadoop/mr_pro/Inverted/data/
hadoop fs -mkdir -p mapreduce/inverted/input
hadoop fs -put *.txt mapreduce/inverted/input
hadoop fs -ls mapreduce/inverted/input
5.3 添加 MapReduce 编程框架
MapReduce 编程框架分为三个部分,请在 Eclipse 中的 Inverted 下分别创建如下四个类:
MyMapper、MyCombiner、MyReducer、MyRunner
接着在类中编写代码。
5.4 Map过程
在src上,单击右键->New->Class->Name处填MyMapper->Finish,MyMapper的完整代码与解析如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import java.io.*;
import java.util.StringTokenizer;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class MyMapper extends Mapper<Object,Text,Text,Text>{
private Text keyInfo = new Text();
private Text valueInfo = new Text();
private FileSplit split;
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
split = (FileSplit)context.getInputSplit();
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
keyInfo.set(itr.nextToken()+" "+split.getPath().getName().toString());
valueInfo.set("1");
context.write(keyInfo,valueInfo);
}
}
}
5.5 Combine过程
在src上,单击右键->New->Class->Name处填MyCombine->Finish,MyCombine的完整代码与解析如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
import java.io.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Reducer;
public class MyCombiner extends Reducer<Text,Text,Text,Text>{
private Text info = new Text();
public void reduce(Text key,Iterable<Text>values,Context context)
throws IOException, InterruptedException{
int sum = 0;
for(Text value:values){
sum += Integer.parseInt(value.toString());
}
String record = key.toString();
String[] str = record.split(" ");
key.set(str[0]);
info.set(str[1]+":"+sum);
context.write(key,info);
}
}
5.6 Reduce过程
在src上,单击右键->New->Class->Name处填MyReducer->Finish,MyReducer的完整代码与解析如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer<Text,Text,Text,Text>{
private Text result = new Text();
public void reduce(Text key,Iterable<Text>values,Context context) throws
IOException, InterruptedException{
String value =new String();
for(Text value1:values){
value += value1.toString()+" ; ";
}
result.set(value);
context.write(key,result);
}
}
5.7 执行MapReduce过程
在src上,单击右键->New->Class->Name处填MyRunner->Finish,MyRunner的完整代码与解析如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(MyRunner.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setCombinerClass(MyCombiner.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
5.8 实验结果
将项目导出为 Inverted.jar ,导出路径为当前项目的target目录下,
在master节点上切换到 jar 包所在目录,输入以下命令到集群运行:
1
2
cd /course/hadoop/mr_pro/Inverted/target
hadoop jar Inverted.jar mapreduce/inverted/input mapreduce/inverted/output
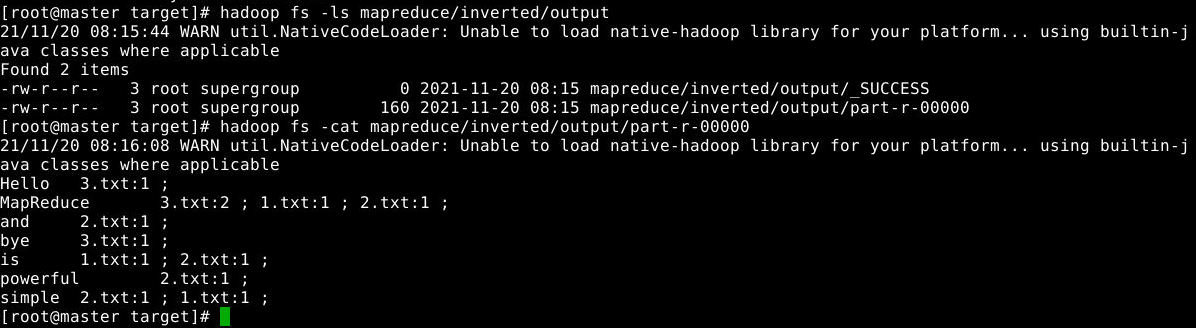
使用以下命令查看计算结果:
1
2
hadoop fs -ls mapreduce/inverted/output
hadoop fs -cat mapreduce/inverted/output/part-r-00000