Hadoop实验3:HDFS编程
实验3:HDFS编程
1 HDFS文件系统编程框架
以下代码为HDFS文件系统的编程框架:
1
2
3
4
5
6
7
8
9
10
11
12
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
public class FileExist {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
}catch(Exception e) {
e.printStackTrace();
}
}
}
上述代码的第7行到第8行为根据配置(Configuration)创建文件系统。文件编程的接口大多都是基于FileSystem类提供的方法进行的,在获得fs对象后,就可以对文件进行操作了。
FileSystem类中各方法的详细含义可参考:https://hadoop.apache.org/docs/current/api/org/apache/hadoop/fs/FileSystem.html
2 实验准备
2.1 创建工作目录
本实验的工作目录为~/course/hadoop/hdfs_pro,使用以下命令创建和初始化工作目录:
1
2
mkdir -p ~/course/hadoop/hdfs_pro
cd ~/course/hadoop/hdfs_pro
2.2 启动Docker和Hadoop集群
首先按照顺序启动四个Docker容器
1
2
3
4
docker start master
docker start slave1
docker start slave2
docker start slave3
接着使用以下命令,进入到master环境内:
1
docker exec -it --privileged master /bin/bash
然后在master容器内启动Hadoop服务
1
2
3
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
2.3 创建eclipse工程
接下来创建eclipse工程:
在终端输入eclipse&命令从后台启动Eclipse IDE环境。
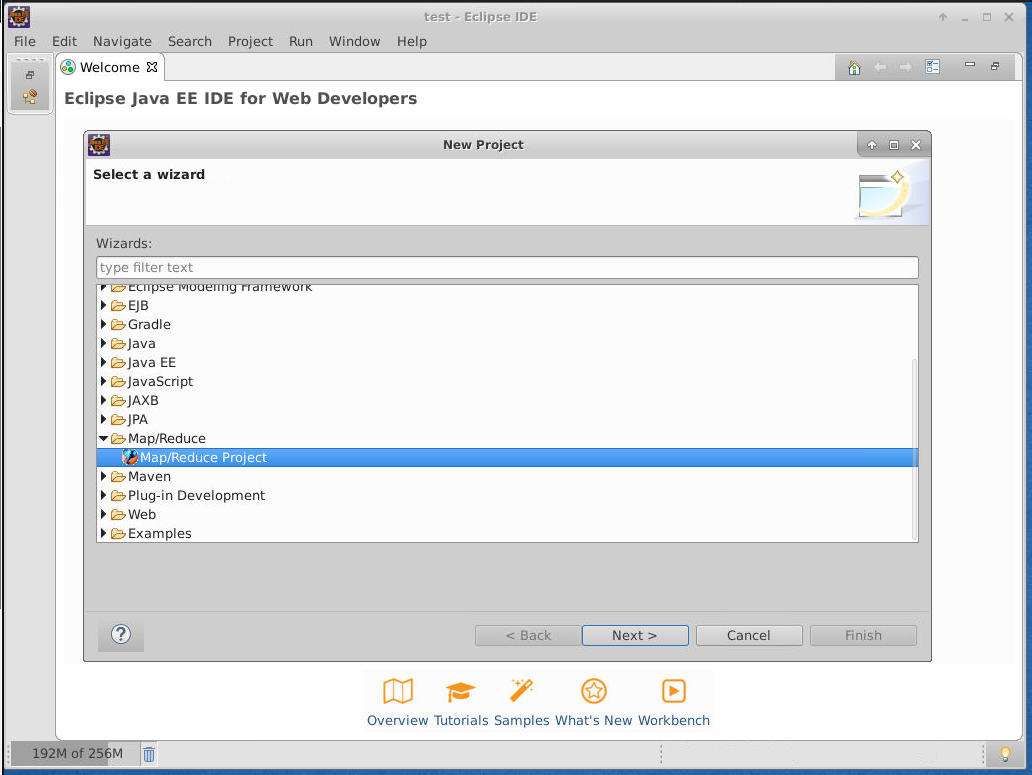
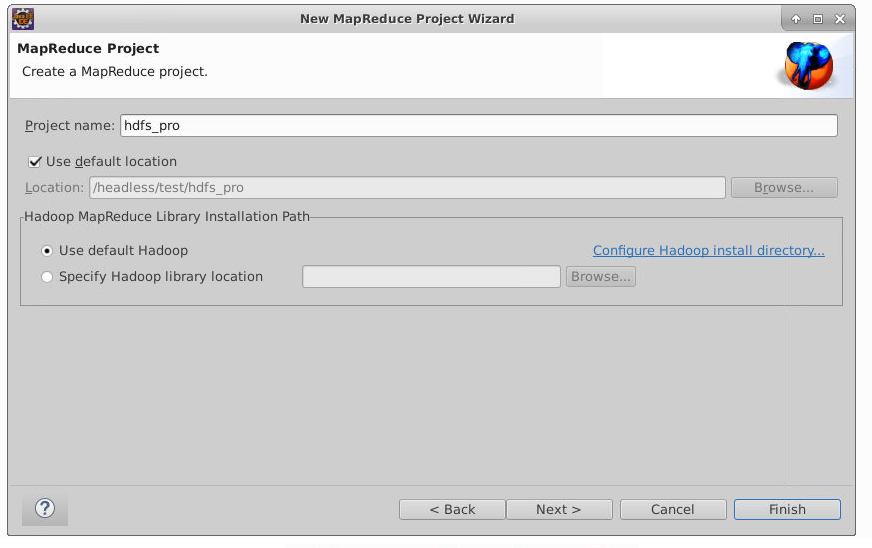
依次点击:File->New->Project->Map/Reduce Project->Next。
在项目名称(Project Name)处填入hdfs_pro,将工程位置选择为本实验的工作目录,再点击Finish。
如下图所示:
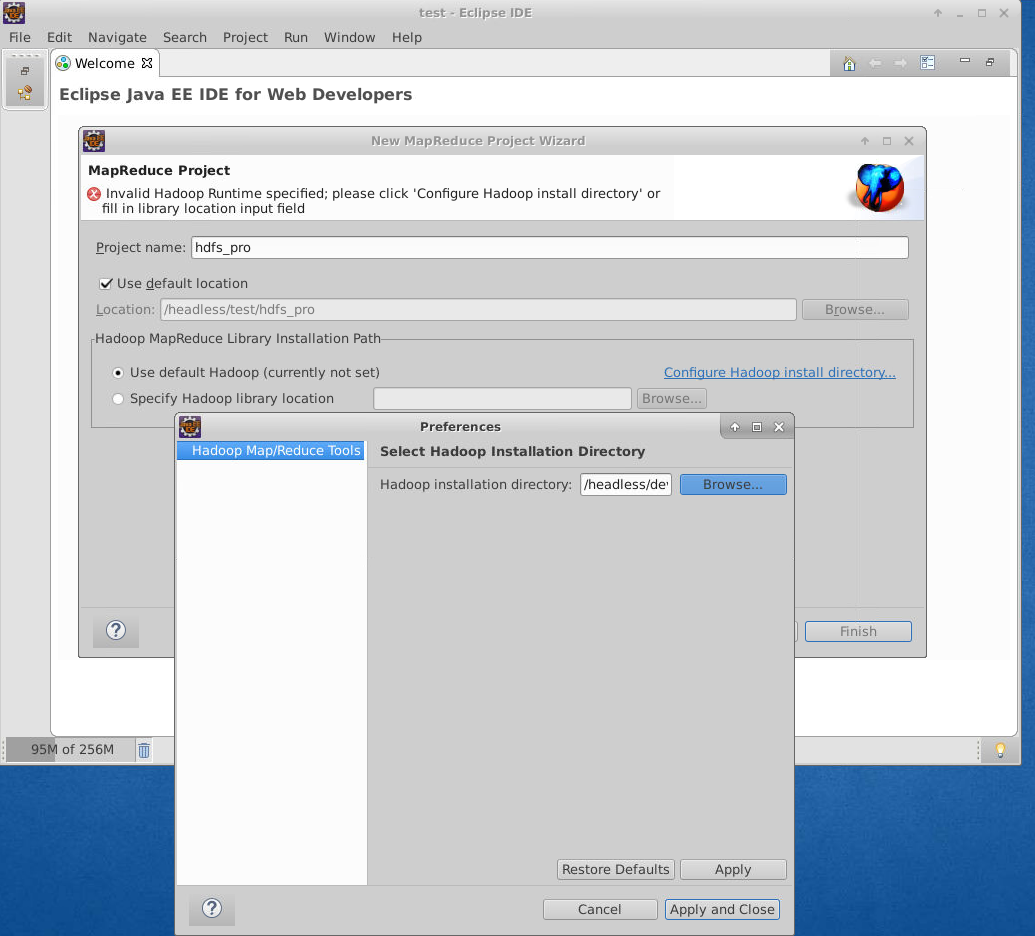
如果需要设置hadoop路径,点击Configure Hadoop install directory...,选择hadoop路径为/headless/dev/hadoop-2.7.1,如下所示:
3 目录相关操作
3.1 创建目录
3.1.1 相关接口说明
创建目录可以使用FileSystem的mkdirs方法,该方法的含义如下:
- 函数原型:
public boolean mkdirs(Path f) throws IOException - 函数功能:调用该方法,根据f指定的路径创建目录。目录的权限为默认权限。
- 参数说明:
f,Path对象。表示要创建的目录的路径。 - 返回值:如果目录成功创建,返回
true。 - 异常:如果遇到IO故障,抛出
IOException异常。
mkdirs还有一个带有目录权限参数的版本,其原型为:
1
public abstract boolean mkdirs(Path f, FsPermission permission) throws IOException
3.1.2 完整实验代码
将 hdfs_pro 项目下 src 目录新建名为 CreateDir 的类
(选中src文件夹->File->new->Class->在name选项中填入 CreateDir->Finish)
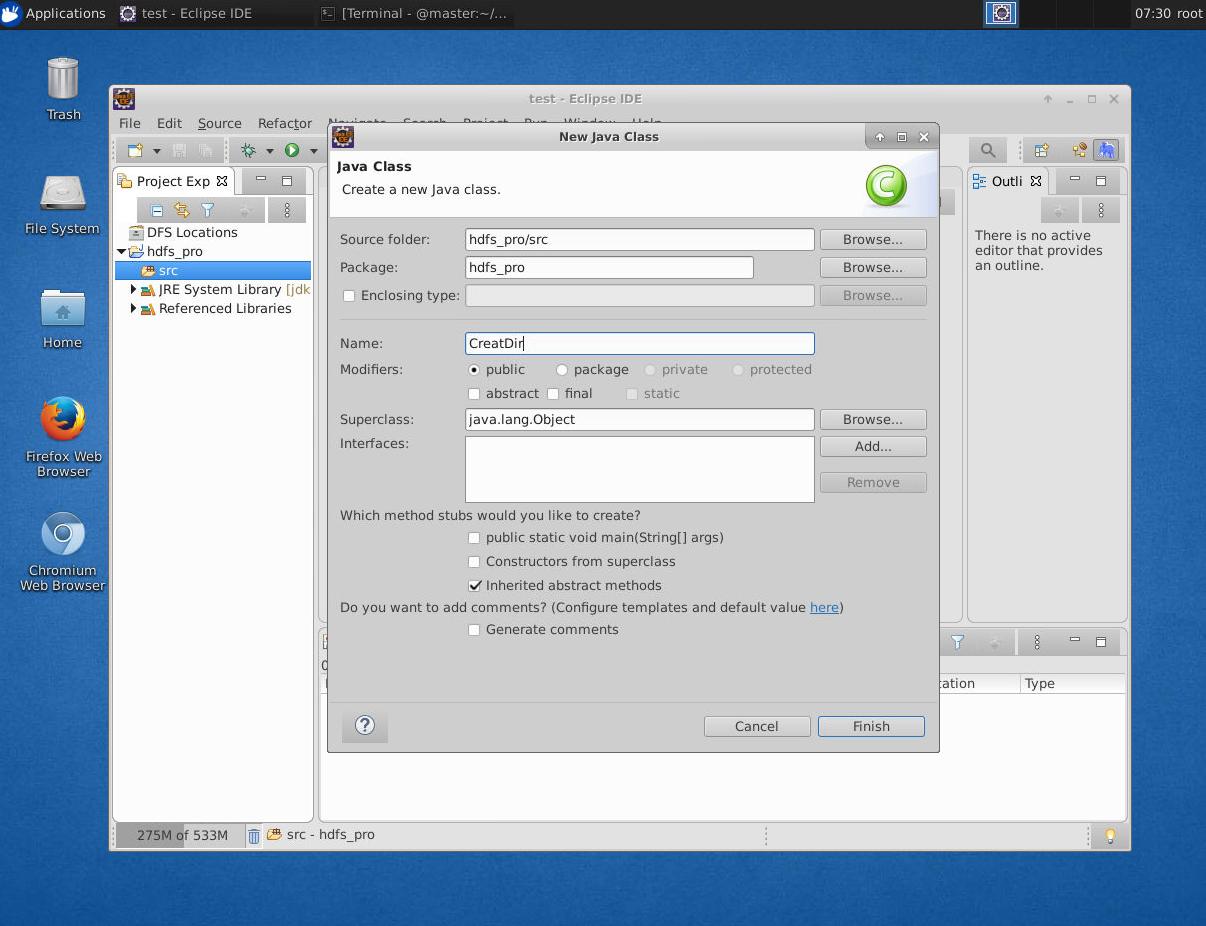
该实验的完整实验代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class CreateDir {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
String dirPath = args[0]; // 新建目录的路径由外部传入
Path hdfsPath = new Path(dirPath);
if(fs.mkdirs(hdfsPath)){
System.out.println("Directory "+ dirPath +" has been created successfully!");
}
}catch(Exception e) {
e.printStackTrace();
}
}
}
将该代码拷贝到CreateDir.java文件中。如下图所示:
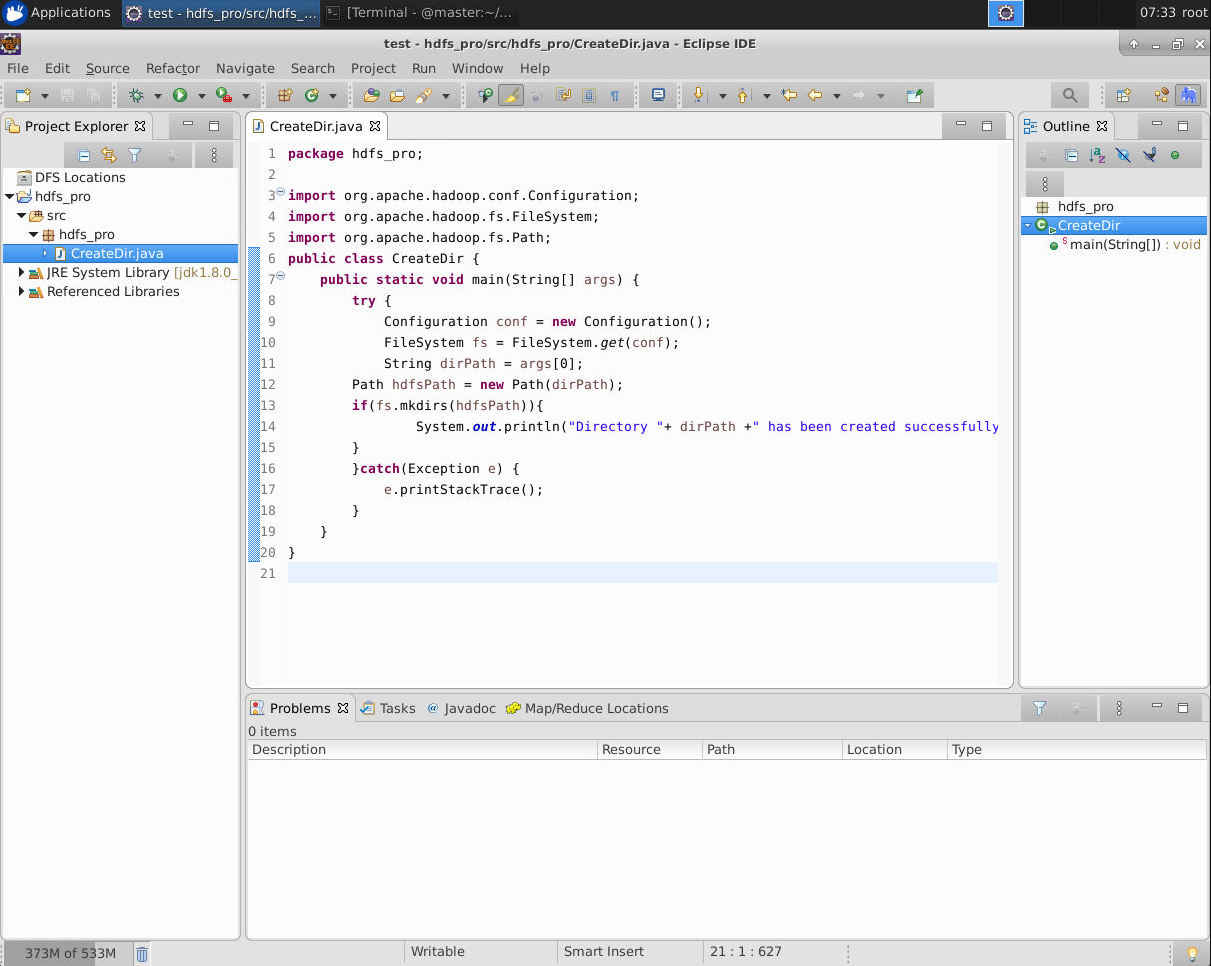
以上代码中主要调用fs的mkdirs方法来创建目录,如果目录创建成功,会输出相应提示信息。
3.1.3 运行结果分析
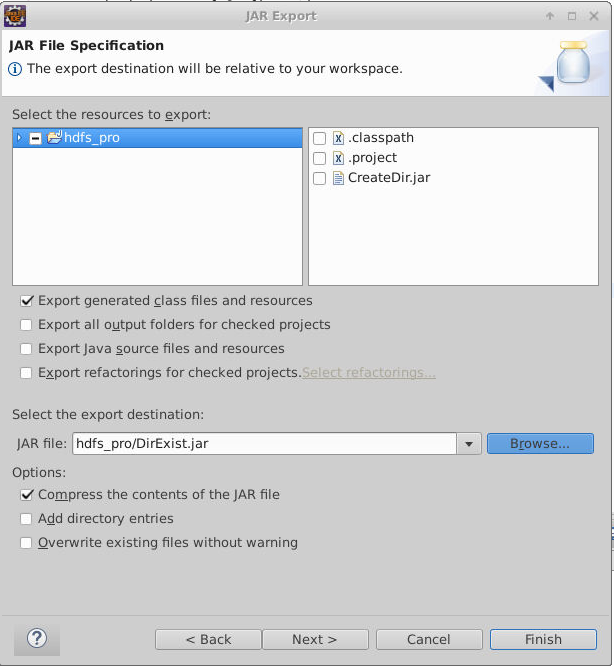
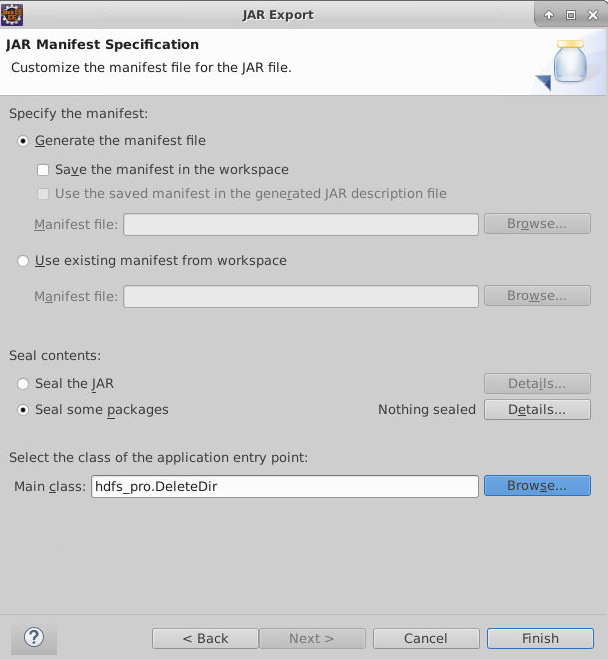
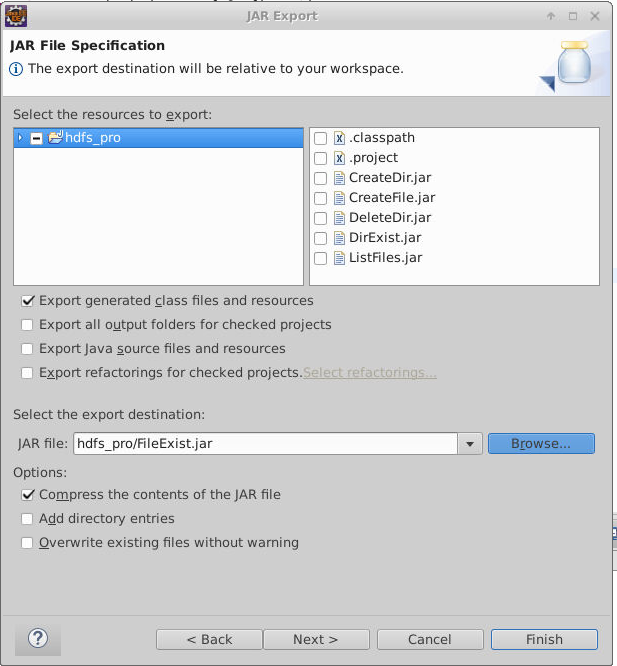
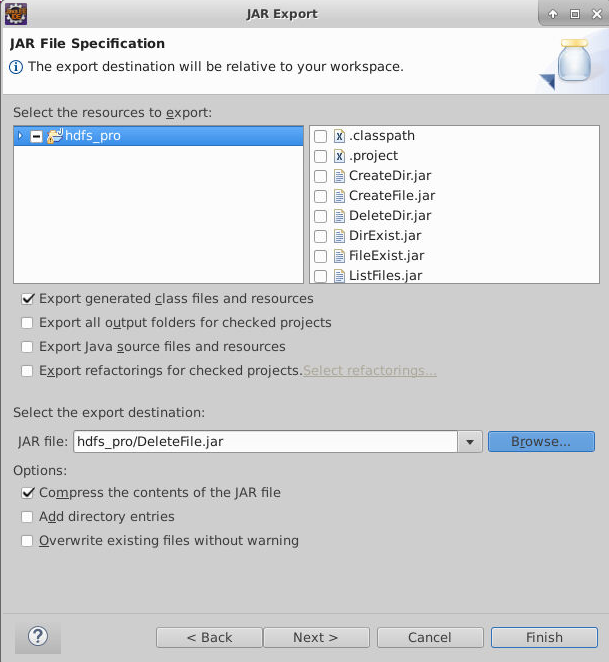
在CreateDir.java上,点击右键,选择Export ,导出 Jar 包。
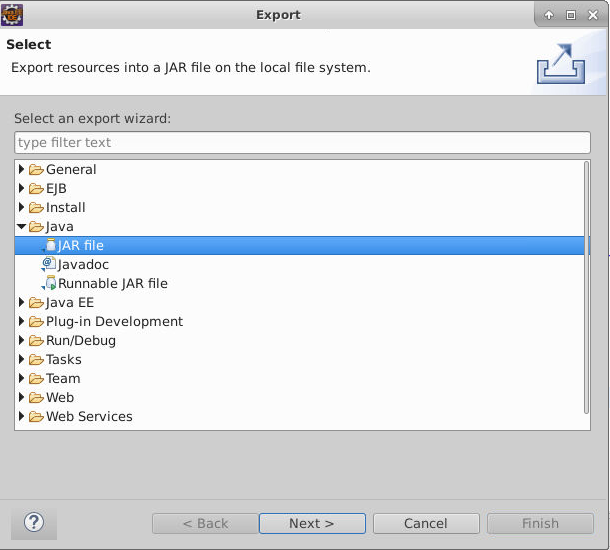
注意选择导出的路径为本实验的工作目录。
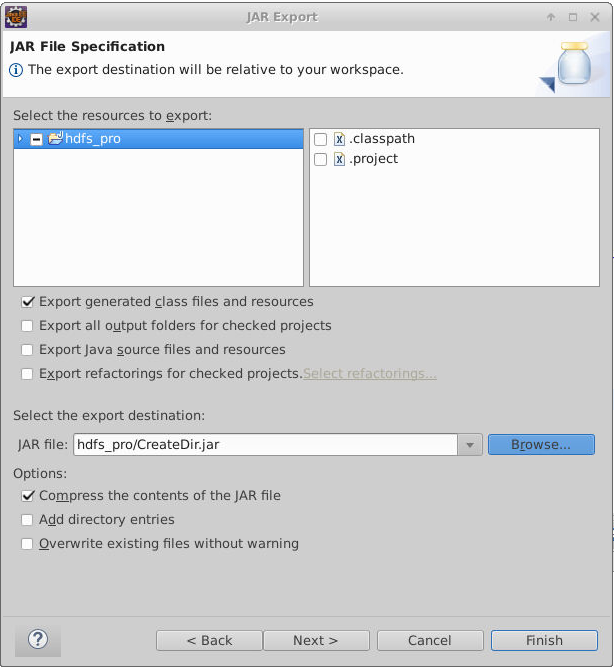
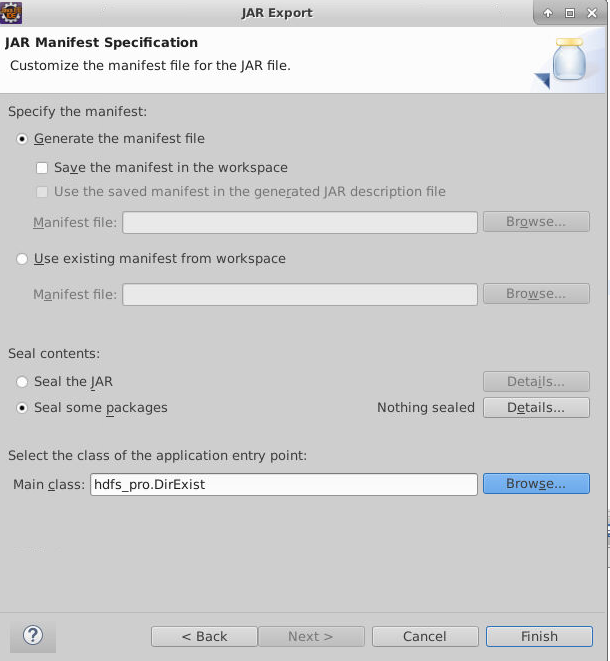
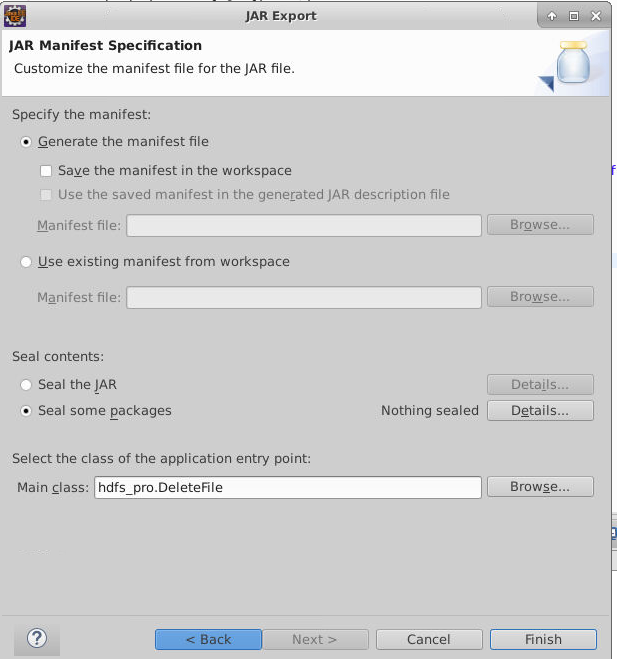
最后设置MainClass
新建一个终端,切换到jar包所在的目录,然后将导出的jar包传到master节点上。
进入master节点,查看hdfs文件系统上当前目录下的内容,然后输入如下hadoop jar命令创建目录,最后再查看是否创建成功:
1
2
3
4
docker exec -it --privileged master /bin/bash
hadoop fs -ls .
hadoop jar /cgsrc/CreateDir.jar newdir
hadoop fs -ls .
运行结果的截图如下:
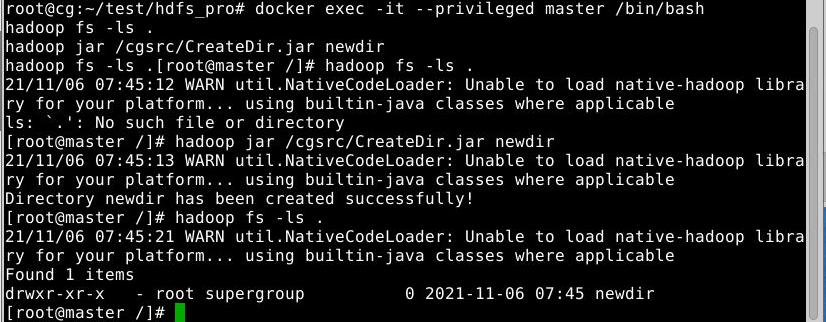
如图所示,目录newdir 已经被成功创建。
3.2 目录存在性判断
3.2.1 相关接口说明
判断文件是否存在需要使用FileSystem的exists方法,该方法的详细含义如下:
方法名:exists
方法原型:public boolean exists(Path f) throws IOException
接口功能:检查某个路径所指的目录是否存在。
接口说明:参数f的含义为源路径。如果目录存在,返回值为true。如果IO故障会抛出IOException异常。
3.2.2 完整实验代码
将 hdfs_pro项目下src目录新建名为DirExist的类
(选中src文件夹->File->new->Class->在name选项中填入 DirExist->Finish)
该实验的完整代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class DirExist {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
String dirName = args[0];
if(fs.exists(new Path(dirName ))) {
System.out.println("Directory Exists!");
} else {
System.out.println("Directory not Exists!");
}
}catch(Exception e) {
e.printStackTrace();
}
}
}
3.2.3 运行结果分析
使用和上一节相同的方法导出 DirExist.jar,并导出到master节点上,并在master节点上使用如下hadoop jar命令提交运行。
1
hadoop jar /cgsrc/DirExist.jar newdir
结果如下:
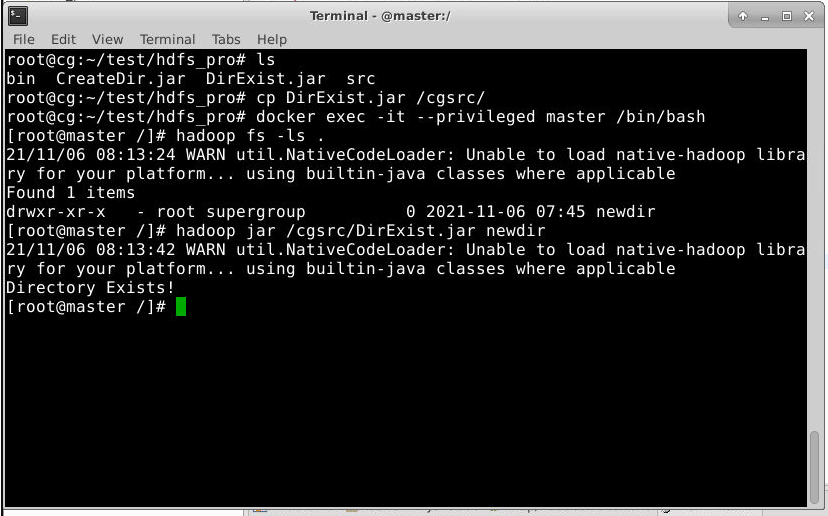
如图所示,程序判断无误。
3.3 列出目录中的内容
3.3.1 相关接口说明
在HDFS文件系统上浏览某个目录中子文件和子目录时,需要使用FileSystem类提供的listStatus方法,该方法将返回该目录下所有子文件和子目录的详细信息,包括文件的长度、块大小、备份数、修改时间、所有者以及权限等信息,这些信息都被封装在FileStatus对象中。调用listStatus方法时需要提供目录的路径,listStatus方法的详细说明如下:
函数原型:public abstract FileStatus[] listStatus(Path f) throws FileNotFoundException, IOException
函数功能:根据输入参数f所指定的目录,列出该目录下所有子文件/子目录的详细信息。注意,该接口不保证返回的文件/目录信息是有序的。
函数参数:f,指定目录的路径。
返回值:f所指定的目录下所有子文件/子目录的详细信息。
异常:两种异常,FileNotFoundException和IOException。当所指定的目录不存在时,抛出FileNotFoundException异常。当遇到IO故障时,返回IOException异常。
3.3.2 完整实验代码
将 hdfs_pro项目下 src 目录新建名为 ListFiles 的类
(选中src文件夹->File->new->Class->在name选项中填入 ListFiles->Finish)
该实验的完整代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
public class ListFiles {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
String filePath = args[0];
Path srcPath = new Path(filePath);
FileStatus[] stats = fs.listStatus(srcPath);
Path[] paths = FileUtil.stat2Paths(stats);
for(Path p : paths)
System.out.println(p.getName());
}catch(Exception e) {
e.printStackTrace();
}
}
}
3.3.3 运行结果分析
使用和上节相同的方法导出 ListFiles.jar,并导出到master节点上,并在master节点上使用如下hadoop jar命令提交运行。
1
hadoop jar ListFiles.jar .
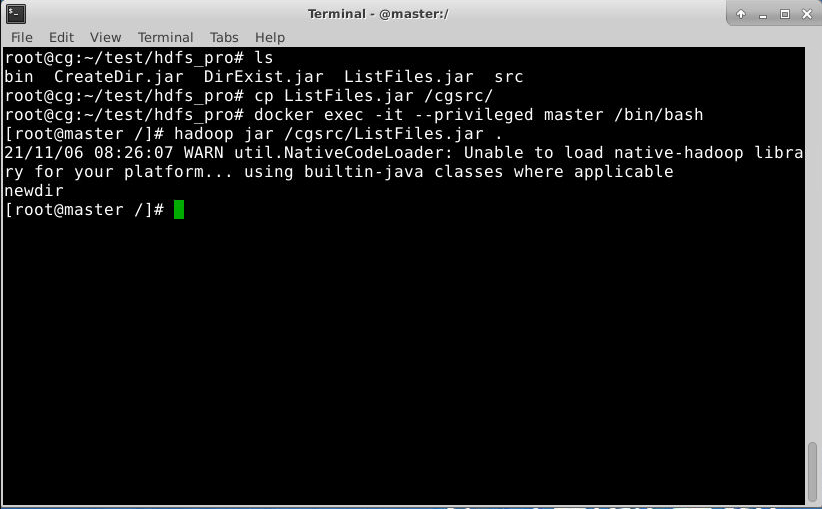
如图,程序成功列出了mydir目录下的所有文件。(如果当前目录没有newDir文件夹,可使用前面步骤提到的方法创建该文件夹,再进入该文件夹下继续创建文件夹,最后退出该文件夹后运行该jar包查看实验效果)。
3.4 删除目录
3.4.1 相关接口说明
删除文件可以使用FileSystem的delete接口,该接口的含义如下:
- 函数原型:
public abstract boolean delete(Path f,boolean recursive) throws IOException - 函数功能:删除文件或者目录。
- 参数说明:
f,要删除的文件或者目录的路径。recursive,是否需要递归删除。如果是删除目录的话,将该参数设置为true。否则,设置为false. - 返回值:如果成功删除,则返回
true。否则,返回false。 - 如果遇到IO故障,会抛出
IOException。
3.4.2 完整实验代码
将 hdfs_pro项目下 src 目录新建名为DeleteDir的类
(选中src文件夹->File->new->Class->在name选项中填入 DeleteDir->Finish)
该实验的完整代码如下所示:
1
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;public class DeleteDir { public static void main(String[] args) { try { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); String dirPath = args[0]; Path hdfsPath = new Path(dirPath); if(fs.delete(hdfsPath,true)){ System.out.println("Directory "+ dirPath +" has been deleted successfully!"); } }catch(Exception e) { e.printStackTrace(); } }}
3.4.3 运行结果分析
使用和上节相同的方法导出DeleteDir.jar,并导出到master节点上,并在master节点上使用如下hadoop jar命令提交运行。
1
hadoop jar DeleteDir.jar newdir
运行结果如下:
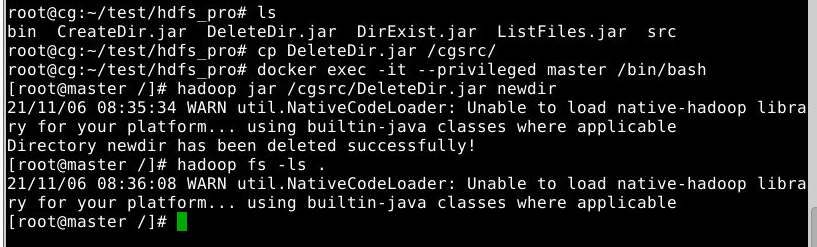
可以看到,上一节创建的 newdir 目录被成功删除。
4 文件的相关操作
4.1 创建文件
4.1.1 相关接口说明
使用FileSystem的create函数可以创建文件,根据参数的不同,create函数有以下几种重载类型:
1
public FSDataOutputStream create(Path f) throws IOExceptionpublic FSDataOutputStream create(Path f,boolean overwrite) throws IOExceptionpublic FSDataOutputStream create(Path f,Progressable progress) throws IOExceptionpublic FSDataOutputStream create(Path f,short replication) throws IOExceptionpublic FSDataOutputStream create(Path f,short replication,Progressable progress) throws IOExceptionpublic FSDataOutputStream create(Path f,boolean overwrite,int bufferSize) throws IOExceptionpublic FSDataOutputStream create(Path f,boolean overwrite,int bufferSize,Progressable progress) throws IOExceptionpublic FSDataOutputStream create(Path f,boolean overwrite,int bufferSize,short replication,long blockSize) throws IOExceptionpublic FSDataOutputStream create(Path f,boolean overwrite,int bufferSize,short replication,long blockSize,Progressable progress)throws IOExceptionpublic abstract FSDataOutputStream create(Path f,FsPermission permission,boolean overwrite,int bufferSize,short replication,long blockSize,Progressable progress) throws IOExceptionpublic FSDataOutputStream create(Path f,FsPermission permission,EnumSet<CreateFlag> flags,int bufferSize,short replication,long blockSize,Progressable progress) throws IOExceptionpublic FSDataOutputStream create(Path f,FsPermission permission,EnumSet<CreateFlag> flags,int bufferSize, short replication,long blockSize,Progressable progress, org.apache.hadoop.fs.Options.ChecksumOpt checksumOpt) throws IOException
上述接口中,各参数的含义分别如下:
f,要打开的文件名,默认会覆盖已经存在的文件。
overwrite,如果要创建的文件已经存在,是否覆盖。设置为true时,覆盖;为false时,不覆盖。
progress,用于汇报进度信息。
replication,设置文件块的副本数量。
bufferSize,所使用的缓冲区的大小。
blockSize,块大小。
permission,设置文件的权限。
flags,指定文件创建标志,文件创建标志包括:CREATE,APPEND,OVERWRITE ,SYNC_BLOCK ,LAZY_PERSIST ,APPEND_NEWBLOCK等。
4.1.2 完整实验代码
将 hdfs_pro项目下 src 目录新建名为 CreateFile 的类
(选中src文件夹->File->new->Class->在name选项中填入CreateFile->Finish)
此次实验的完整代码如下所示:
1
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;public class CreateFile { public static void main(String[] args) { try { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); String filePath = args[0]; Path hdfsPath = new Path(filePath); fs.create(hdfsPath); }catch(Exception e) { e.printStackTrace(); } }}
4.1.3 运行结果分析
使用和上节相同的方法导出 CreateFile.jar,并导出到master节点上,并在master节点上使用如下hadoop jar命令提交运行(执行命令前记得切换到CreateFile.jar所在目录/cgsrc,后续步骤不再赘述)。
1
hadoop jar CreateFile.jar newfile.txt
运行结果如下:
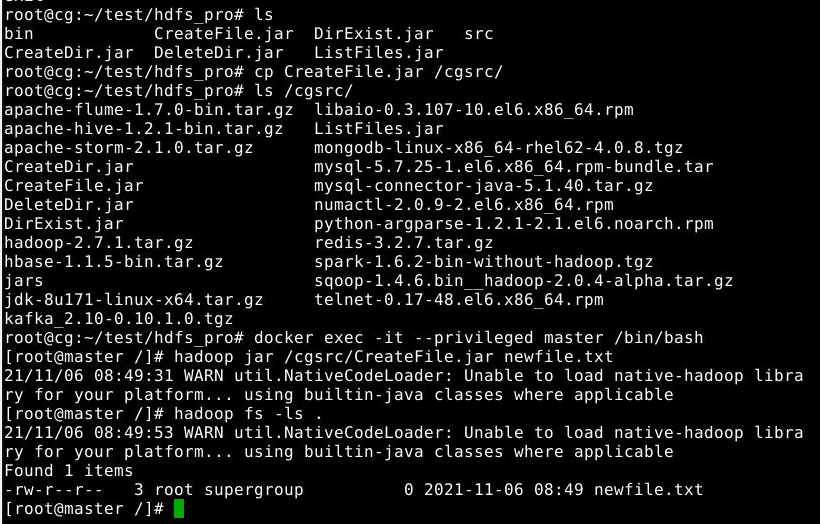
如图所示,文件已经成功被创建。
4.2 文件存在性判断
4.2.1 相关接口说明
判断文件是否存在需要使用FileSystem的exists方法,该方法的详细含义如下:
方法名:exists
方法原型:public boolean exists(Path f) throws IOException
接口功能:检查某个路径所指的文件是否存在。
接口说明:参数f的含义为源路径。如果文件存在,返回值为true。如果IO故障会抛出IOException异常。
4.2.2 完整实验代码
该实验的完整代码如下:
1
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;public class FileExist { public static void main(String[] args) { try { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); String fileName = args[0]; if(fs.exists(new Path(fileName))) { System.out.println("File Exists!"); } else { System.out.println("File not Exists!"); } }catch(Exception e) { e.printStackTrace(); } }}
4.2.3 运行结果分析
导出FileExist.jar 后,并导出到master节点上,并在master节点上使用如下hadoop jar命令提交运行。
1
hadoop jar FileExist.jar newfile.txt
运行结果如下:
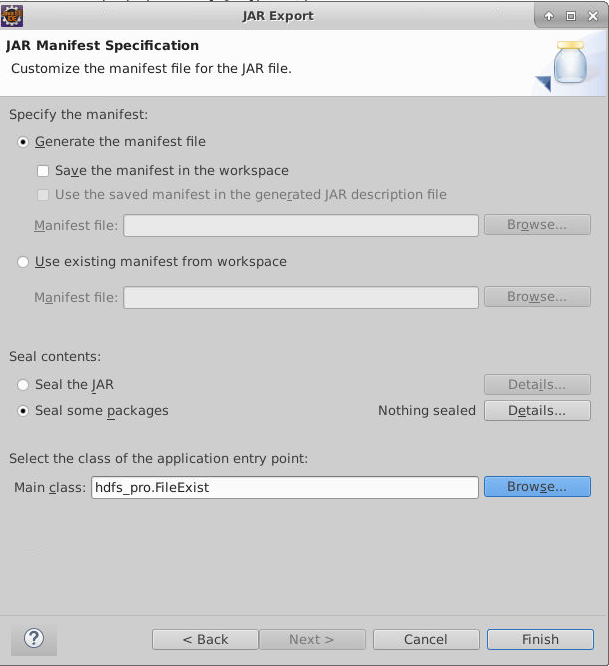
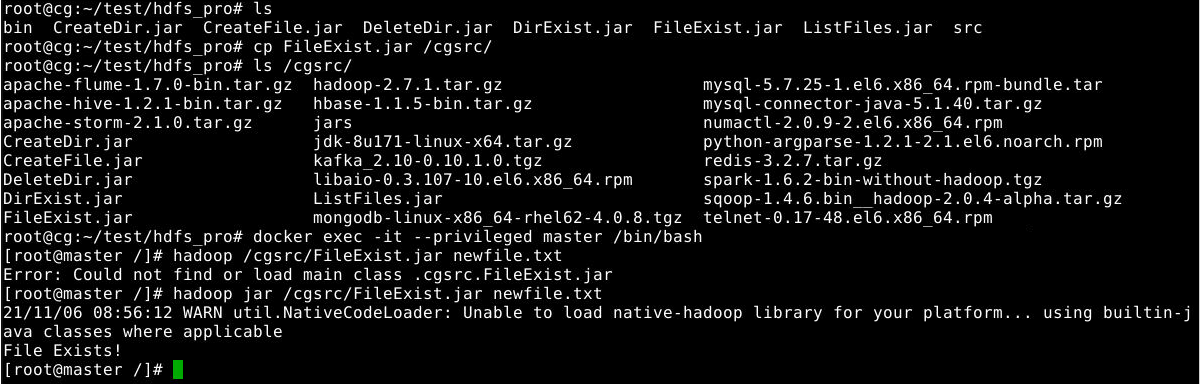
可以发现newfile.txt存在。
4.3 文件写
4.3.1 相关接口说明
HDFS不支持文件的随机写,写文件的方式有两种:1)文件不存在,创建文件之后,开始对文件的内容进行写入。2)文件存在,打开文件,在文件尾部追加写。
对于第一种方式,由于调用create方法后会返回FSDataOutputStream对象,使用该对象对文件进行写操作。第二种方式,使用FileSystem类的append接口,该接口也会返回FSDataOutputStream对象,同样使用该对象可对文件进行追加操作。
create方法在文件创建实验中已经进行了详细说明,这里对FSDataOutputStream的相关常用方法进行说明,FSDataOutputStream有三个常用的方法,分别为write,flush,close函数。write将数据写入到文件中,flush将数据缓存在内存中的数据更新到磁盘,close则关闭流对象。
FileSystem的append函数详细说明如下:
函数原型:public FSDataOutputStream append(Path f) throws IOException
函数功能:在一个已经存在的文件尾部追加数据。
函数参数:f,文件路径。
返回值:FSDataOutputStream对象。
异常:遇到IO故障时,抛出IOException异常。
4.3.2 完整实验代码
将hdfs_pro项目下 src 目录新建名为 WriteFile 的类
(选中src文件夹依次点击File->new->Class,在name选项中填入WriteFile,最后点击Finish)
该实验的完整代码如下所示:
1
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FSDataOutputStream;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;public class WriteFile { public static void main(String[] args) { try { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); String filePath = args[0]; Path srcPath = new Path(filePath); FSDataOutputStream os = fs.create(srcPath,true,1024,(short)1,(long)(1<<26)); String str = "Hello, this is a sentence that should be written into the file.\n"; os.write(str.getBytes()); os.flush(); os.close(); os = fs.append(srcPath); str = "Hello, this is another sentence that should be written into the file.\n"; os.write(str.getBytes()); os.flush(); os.close(); }catch(Exception e) { e.printStackTrace(); } }}
该代码中,文件的写入分为两部分,第一部分使用create返回的FSDataOutputStream对象进行写入,第二部分使用append返回的FSDataOutputStream对象进行写入。
4.3.3 运行结果分析
导出 WriteFile.jar 后,并导出到master节点上,并在master节点上使用如下hadoop jar命令提交运行。
1
hadoop jar WriteFile.jar WriteFile newfile.txt
运行结果如下:
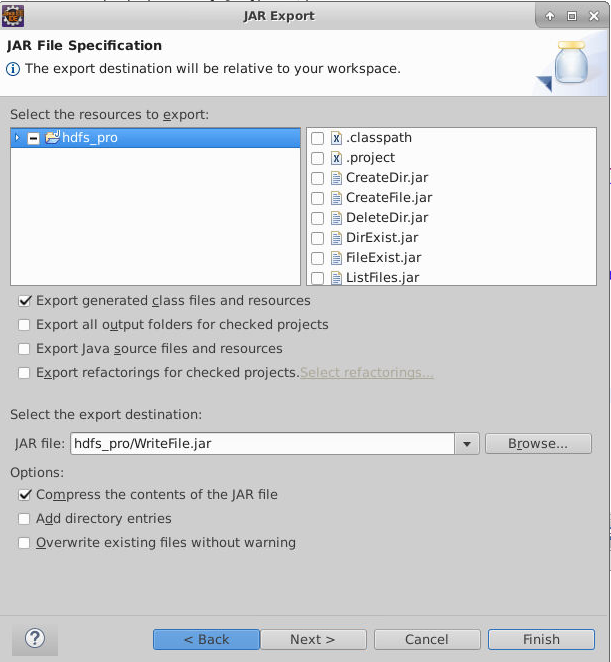
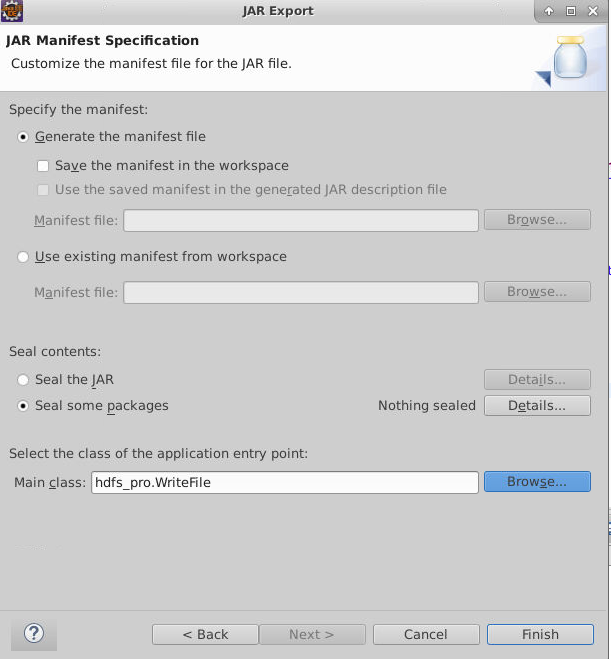
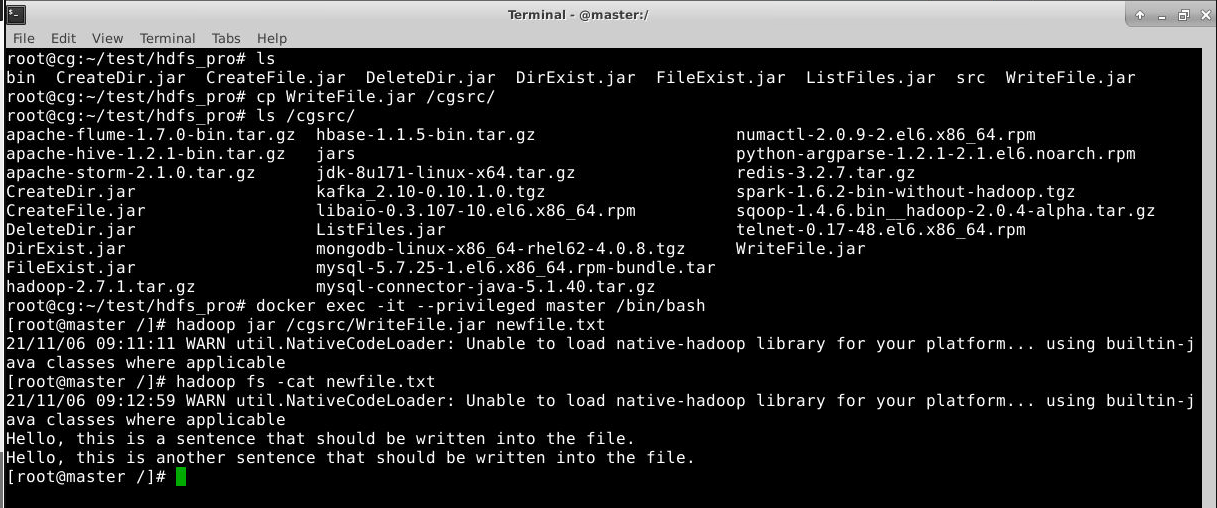
如图所示,文件成功写入。
4.4 文件读
4.4.1 相关接口说明
如果要读取HDFS上的文件,可以使用open方法。open方法会返回一个FSDataInputStream对象,使用该对象可对文件进行读操作。open函数详细说明如下:
函数原型:public FSDataInputStream open(Path f) throws IOException
函数功能:打开Path对象f指定的路径的文件。
参数说明:f,要打开的文件。
返回值:FSDataInputStream对象,利用FSDataInputStream对象可对文件进行读操作。
异常:遇到IO故障时,将抛出IOException。
open方法还有一个带有bufferSize参数的重载版本,该方法的原型为:
1
public abstract FSDataInputStream open(Path f,int bufferSize) throws IOException
其中,bufferSize的含义为读取过程中所使用的缓冲区的大小。
4.4.2 完整实验代码
将 hdfs_pro项目下 src 目录新建名为 ReadFile 的类
(选中src文件夹->File->new->Class->在name选项中填入ReadFile->Finish)
该实验的完整代码如下:
1
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FSDataInputStream;import org.apache.hadoop.fs.FSDataOutputStream;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;public class ReadFile { public static void main(String[] args) { try { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); String filePath = args[0]; Path srcPath = new Path(filePath); FSDataInputStream is = fs.open(srcPath); while(true) { String line = is.readLine(); if(line == null) { break; } System.out.println(line); } is.close(); }catch(Exception e) { e.printStackTrace(); } }}
4.4.3 运行结果分析
导出ReadFile.jar后,并导出到master节点上,并在master节点上使用如下hadoop jar命令提交运行。
1
hadoop jar ReadFile.jar newfile.txt
运行结果如下:
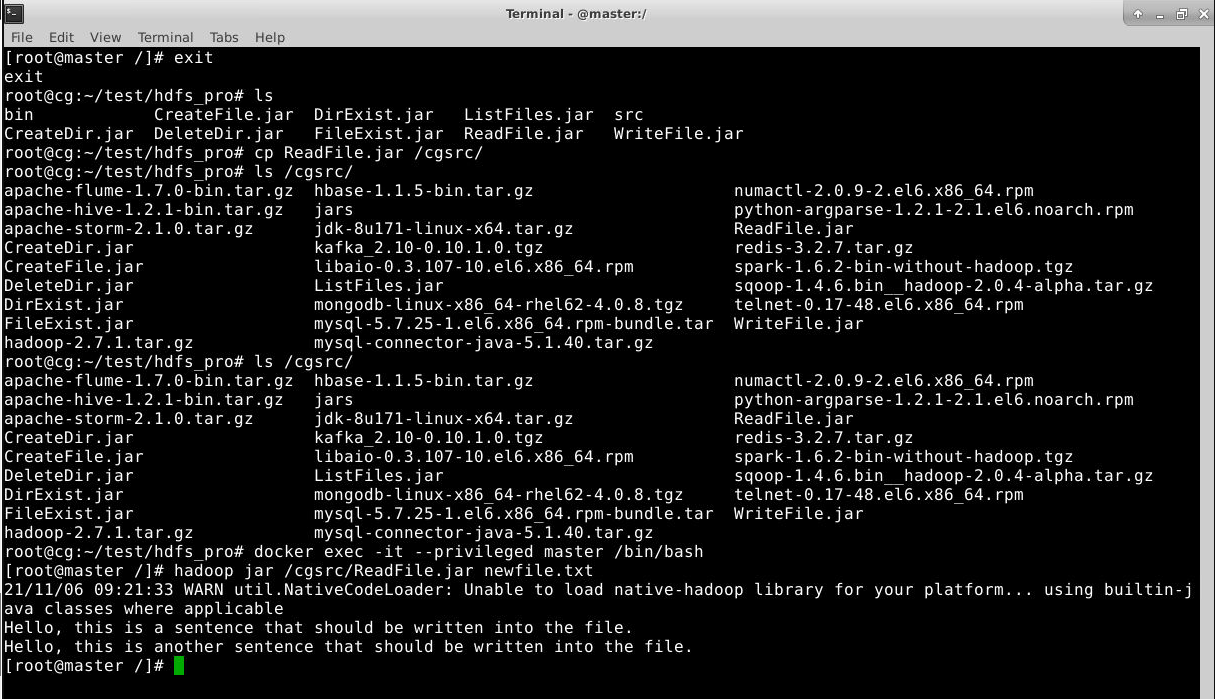
如图,文件中的内容成功被读取。
4.5 文件重命名
4.5.1 相关接口说明
文件重命名可以使用FileSystem的rename方法,该方法的详细说明如下:
函数原型:public abstract boolean rename(Path src,Path dst)throws IOException
函数功能:将路径src重命名为路径dst。
参数:src,将被重命名的路径。dst,重命名后的路径。
返回值:如果重命名成功,返回true;否则,返回false;
异常:如果遇到IO故障,抛出IOException异常。
4.5.2 完整实验代码
将 hdfs_pro项目下 src 目录新建名为 Rename 的类
(选中src文件夹->File->new->Class->在name选项中填入Rename->Finish)
该实验的完整代码如下:
1
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;public class Rename { public static void main(String[] args) { try { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); String srcStrPath = args[0]; String dstStrPath = args[1]; Path srcPath = new Path(srcStrPath); Path dstPath = new Path(dstStrPath); if(fs.rename(srcPath,dstPath)) { System.out.println("rename from " + srcStrPath + " to " + dstStrPath + "successfully!"); } }catch(Exception e) { e.printStackTrace(); } }}
4.5.3 运行结果分析
导出 Rename.jar 后,并导出到master节点上,并在master节点上使用如下hadoop jar命令提交运行。
1
hadoop jar Rename.jar newfile.txt file.txt
运行结果如下:
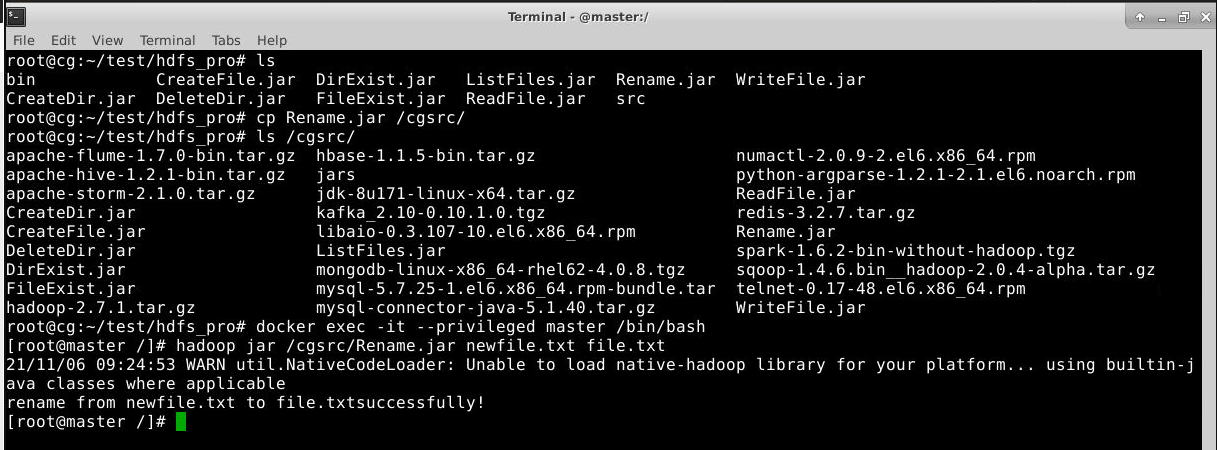
如图可以发现文件已经重命名。
4.6 文件删除
4.6.1 相关接口说明
删除文件可以使用FileSystem的delete接口,该接口的含义如下:
- 函数原型:
public abstract boolean delete(Path f,boolean recursive) throws IOException - 函数功能:删除文件或者目录。
- 参数说明:
f,要删除的文件或者目录的路径。recursive,是否需要递归删除。如果是删除目录的话,将该参数设置为true。否则,设置为false. - 返回值:如果成功删除,则返回
true。否则,返回false。 - 如果遇到IO故障,会抛出
IOException。
4.6.2 完整实验代码
将 hdfs_pro 项目下 src 目录新建名为 DeleteFile的类
(选中src文件夹->File->new->Class->在name选项中填入DeleteFile->Finish)
该实验的完整代码如下:
1
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;public class DeleteFile { public static void main(String[] args) { try { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); String filePath = args[0]; Path hdfsPath = new Path(filePath); if(fs.delete(hdfsPath,false)){ System.out.println("File "+ filePath +" has been deleted successfully!"); } }catch(Exception e) { e.printStackTrace(); } }}
4.6.3 运行结果分析
导出 DeleteFile.jar 后,并导出到master节点上,并在master节点上使用如下hadoop jar命令提交运行。
1
hadoop jar DeleteFile.jar file.txt
运行结果如下:
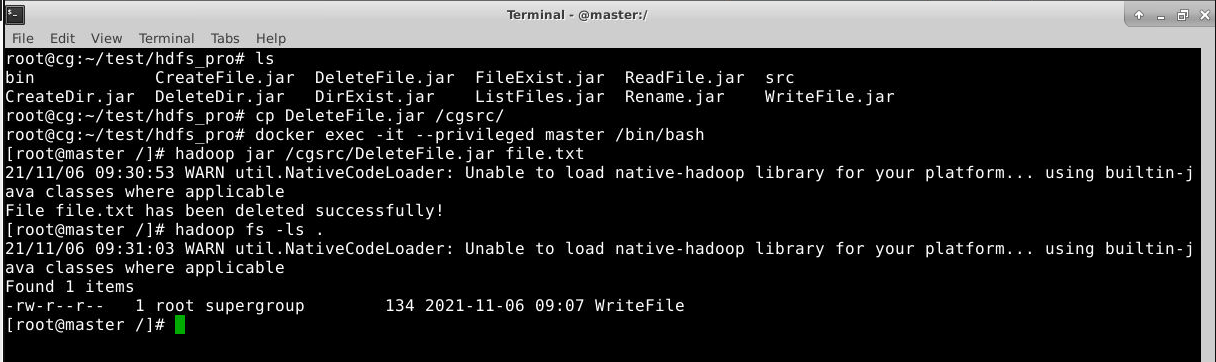
file.txt 已经被删除。