Hadoop实验1:搭建Hadoop集群
1 启动Docker容器
1.1 加载镜像
实验使用的Docker镜像保存在/cg/images/hadoop_node.tar.gz文件中,执行如下命令加载该镜像:
1
docker load < /cg/images/hadoop_node.tar.gz

1.2 启动实验容器
执行如下四个命令,启动四个名称分别为master、slave1、slave2、slave3的docker容器用于实验:
1
docker run --name master --privileged --hostname master --ip 172.18.0.2 --add-host=slave1:172.18.0.3 --add-host=slave2:172.18.0.4 --add-host=slave3:172.18.0.5 -itd -v /cgsrc:/cgsrc:ro -v /headless/course/:/course hadoop_node /service_start.sh
1
docker run --name slave1 --privileged --hostname slave1 --ip 172.18.0.3 --add-host=master:172.18.0.2 --add-host=slave2:172.18.0.4 --add-host=slave3:172.18.0.5 -itd -v /cgsrc:/cgsrc:ro hadoop_node /service_start.sh
1
docker run --name slave2 --privileged --hostname slave2 --ip 172.18.0.4 --add-host=master:172.18.0.2 --add-host=slave1:172.18.0.3 --add-host=slave3:172.18.0.5 -itd -v /cgsrc:/cgsrc:ro hadoop_node /service_start.sh
1
docker run --name slave3 --privileged --hostname slave3 --ip 172.18.0.5 --add-host=master:172.18.0.2 --add-host=slave1:172.18.0.3 --add-host=slave2:172.18.0.4 -itd -v /cgsrc:/cgsrc:ro hadoop_node /service_start.sh
接着,输入docker ps查看执行结果:
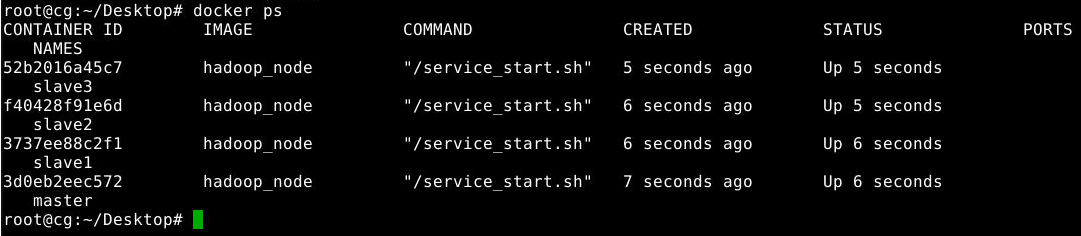
如果发现容器没有启动,不要使用docker start master slave1 slave2 slave3进行并发启动多容器,使用该命令启动容器时,容器的启动先后顺序是不确定的,这可能会导致容器分配到的IP和创建容器时指定的IP不一致,导致集群无法启动。
应该使用
1
2
3
4
docker start master
docker start slave1
docker start slave2
docker start slave3
但是,关闭容器可以使用docker stop master slave1 slave2 slave3
2 配置Hadoop环境
2.1 配置JAVA环境
Hadoop是基于Java语言开发的,因此需要安装Java环境。
2.1.1 进入容器
我们可以使用以下指令进入master容器:
1
docker exec -it --privileged master /bin/bash
同理,也可以使用以下指令分别进入slave1、slave2、slave3容器:
1
2
3
docker exec -it --privileged slave1 /bin/bash
docker exec -it --privileged slave2 /bin/bash
docker exec -it --privileged slave3 /bin/bash
2.1.2 容器内配置Java环境
分别在 master、slave1、slave2、slave3 容器内执行以下操作,完成Java环境的配置。首先在所在容器内使用如下命令从资源文件夹/cgsrc中将JDK安装包复制到/usr/local/java目录下:
1
2
mkdir /usr/local/java
cp /cgsrc/jdk-8u171-linux-x64.tar.gz /usr/local/java/
我们接下来切换到/usr/local/java目录下,将安装包解压,并删除用过的tar文件。
1
2
3
cd /usr/local/java/
tar -zxvf jdk-8u171-linux-x64.tar.gz
rm -f jdk-8u171-linux-x64.tar.gz
此时/usr/local/java目录下仅有一个jdk1.8.0_171目录,这就是Java主目录。
接下来需要配置JAVA_HOME环境变量,为了方便起见,这里直接在~/.bachrc这个文件中进行设置,采用这种配置方式时,只对当前登录的单个用户生效,当该用户登录以及每次打开新的Shell时,它的环境变量文件.bashrc会被读取。输入下面命令打开当前登录用户的环境变量配置文件.bashrc:
1
vim ~/.bashrc
在文件最后面添加如下三行(注意等号前后不能有空格),然后保存退出vim:
1
2
3
export JAVA_HOME=/usr/local/java/jdk1.8.0_171
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
输入以下指令,可以检查Java环境是否正确配置:
1
2
echo $JAVA_HOME
java -version

务必以同样的步骤对每个节点进行配置!
**退出当前容器,可以使用exit指令 **
2.2 配置分布式模式
当Hadoop采用分布式模式部署和运行时,存储采用分布式文件系统HDFS。而且,HDFS的名称节点和数据节点位于不同的机器上。这时,数据就可以分布到多个节点上,不同数据节点上的数据计算可以并行执行,这使得MapReduce分布式计算能力才能真正发挥作用。
本节使用3个虚拟节点搭建集群环境,可以看做是三台物理机器:Master节点和三个Slave节点。节点的IP地址可以在对应的命令行中使用ifconfig命令查看:
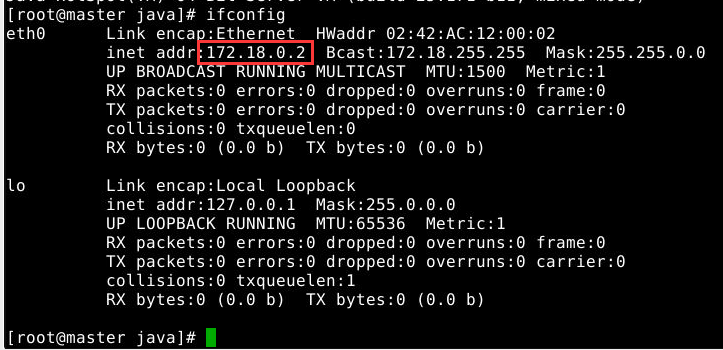
2.3 配置hosts文件
从步骤2.2可以得到,四个节点的ip地址如下:
| 节点 | IP |
|---|---|
| master | 172.18.0.2 |
| slave1 | 172.18.0.3 |
| slave2 | 172.18.0.4 |
| slave3 | 172.18.0.5 |
由于我们在docker的启动命令里已经加入了host配置,所以检查发现/etc/hosts文件里映射关系齐全则可以略过此步骤。
执行如下命令打开并修改master节点中的/etc/hosts文件:
1
cat /etc/hosts
1
2
3
4
172.18.0.2 master
172.18.0.3 slave1
172.18.0.4 slave2
172.18.0.5 slave3
上面完成了master节点的配置,接下来在三个slave节点中使用同样步骤配置hosts文件。
在各个节点上执行如下指令,测试节点之间是否已经联通:
1
2
3
4
ping master -c 2
ping slave1 -c 2
ping slave2 -c 2
ping slave3 -c 2
如果都能连通,则配置成功。
2.4 配置SSH无密码登陆
需要让master节点可以SSH无密码登录到各个slave节点上。
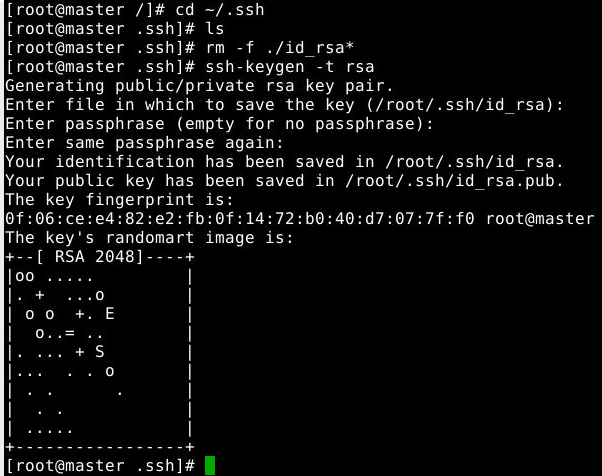
首先,生成master节点的公钥,如果之前已经生成过公钥,必须删除原来的公钥,重新生成一次。具体命令如下:
1
2
3
cd ~/.ssh #如果没有该目录,先执行一次 ssh localhost,密码默认为83953588abc
rm -f ./id_rsa* #删除之前生成的公钥
ssh-keygen -t rsa #执行该命令后,遇到提示信息,均按Enter即可
为了让master节点能无密码SSH登录到本机,需要在master节点上执行如下命令:
1
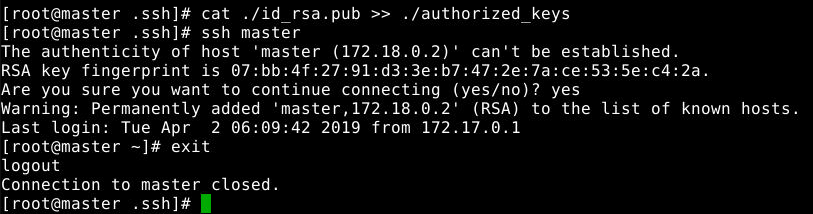
cat ./id_rsa.pub >> ./authorized_keys
完成后可以执行ssh master来验证一下,可能会遇到提示信息,只要输入 yes 即可,测试成功后执行exit命令返回原来的终端。
接下来在master节点上将公钥传输到另外三个slave节点:
1
2
3
scp ~/.ssh/id_rsa.pub root@slave1:/root
scp ~/.ssh/id_rsa.pub root@slave2:/root
scp ~/.ssh/id_rsa.pub root@slave3:/root
执行scp复制文件时会要求输入相应的slave的密码,默认为 83953588abc。
传输完成后在三个slave节点上将SSH公钥加入授权:
1
2
3
mkdir -p ~/.ssh #如果slave节点上已存在该目录,则先删除该目录再执行该命令
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm -f ~/id_rsa.pub
这样就可以在master节点上无密码SSH登录到各个slave节点了。
注意:由于启动Hadoop集群时,master节点需要通过ssh登录自身节点(ssh localhost),为了去掉ssh的交互式认证提示,需要在master节点上执行以下命令:
1
ssh-keyscan localhost >> ~/.ssh/known_hosts
2.5 安装Hadoop并配置环境变量
在master节点上执行如下操作安装hadoop并配置环境变量。
首先将hadoop安装包复制到 /usr/local 目录下:
1
cp /cgsrc/hadoop-2.7.1.tar.gz /usr/local/
切换到/usr/local目录下,对安装包进行解压:
1
2
3
cd /usr/local
tar -zxvf hadoop-2.7.1.tar.gz
rm -f hadoop-2.7.1.tar.gz
解压得到名为hadoop-2.7.1的目录,将其重命名为 hadoop:
1
mv hadoop-2.7.1/ hadoop
之后就可以配置PATH变量了,使我们可以在任何目录下使用hadoop指令。
首先打开 ~/.bashrc 文件:
1
vim ~/.bashrc
然后在该文件最末加入下面一行内容:
1
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
保存后执行 source ~/.bashrc 使配置生效。
之后执行如下命令查看hadoop版本:
1
hadoop version
若得到如下输出则安装成功:

3 配置集群环境
配置集群环境时,需要修改 /usr/local/hadoop/etc/hadoop 目录下的配置文件,这里仅设置正常启动必须的设置项,包括 slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml共五个文件。
以下对master节点的配置文件进行修改。
故,在master容器内输入如下指令,进入到指定目录:
1
cd /usr/local/hadoop/etc/hadoop
3.1 修改文件slaves
需要把所有数据节点的主机名写入该文件,每行一个,默认为localhost(即把本机作为数据节点)。在进行集群配置时,可以保留localhost,让master节点同时充当名称节点和数据节点,也可以删除localhost这行,让master节点仅作为名称节点使用。
使用vim slaves指令编辑文件。
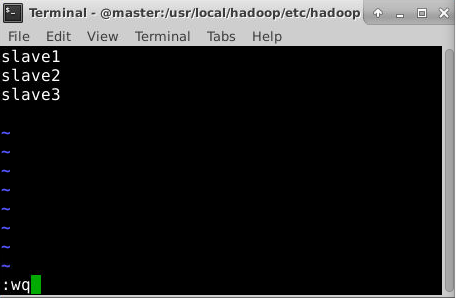
本节让master节点仅作为名称节点使用,因此将slaves文件中原来的内容删除,添加如下内容:
1
2
3
slave1
slave2
slave3
3.2 修改文件core-site.xml
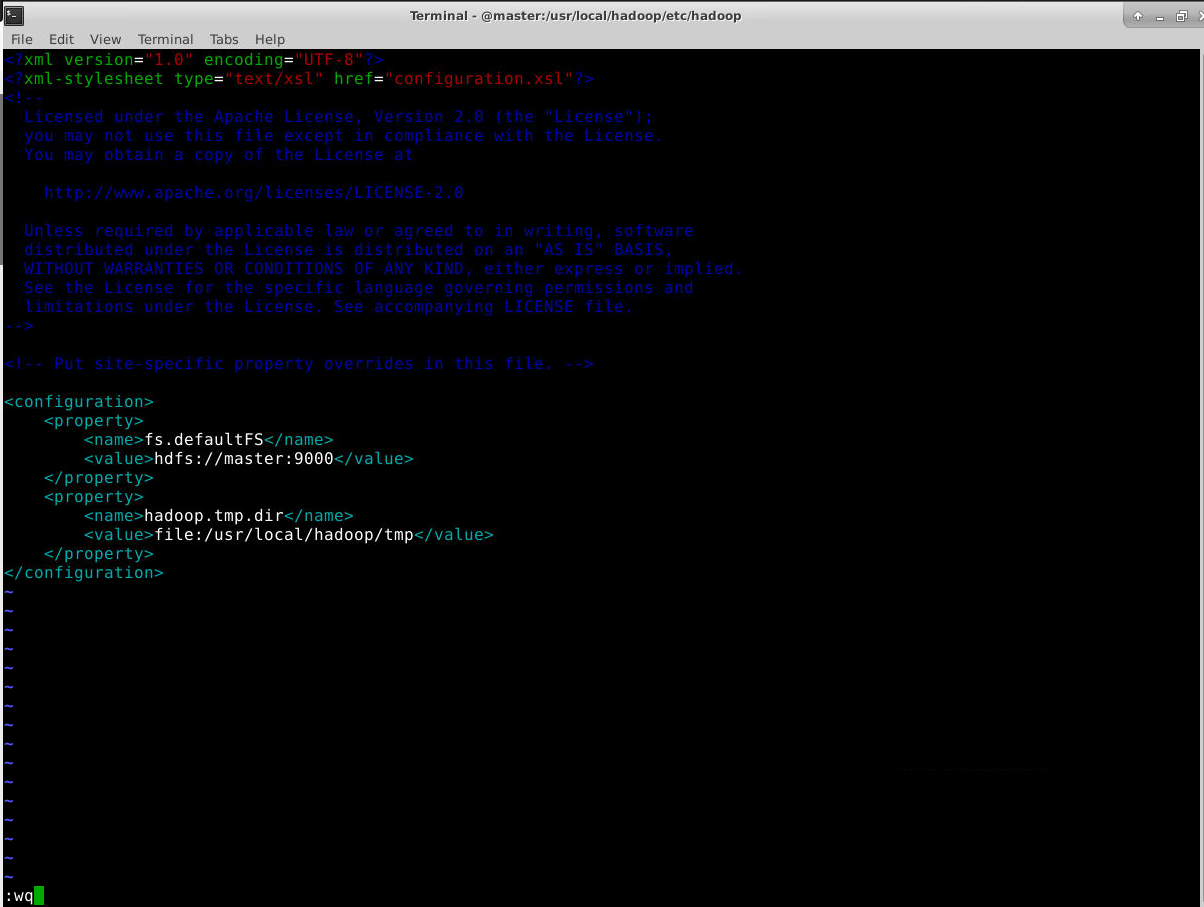
把core-site.xml文件修改为如下内容:
1
2
3
4
5
6
7
8
9
10
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>
3.3 修改文件hdfs-site.xml
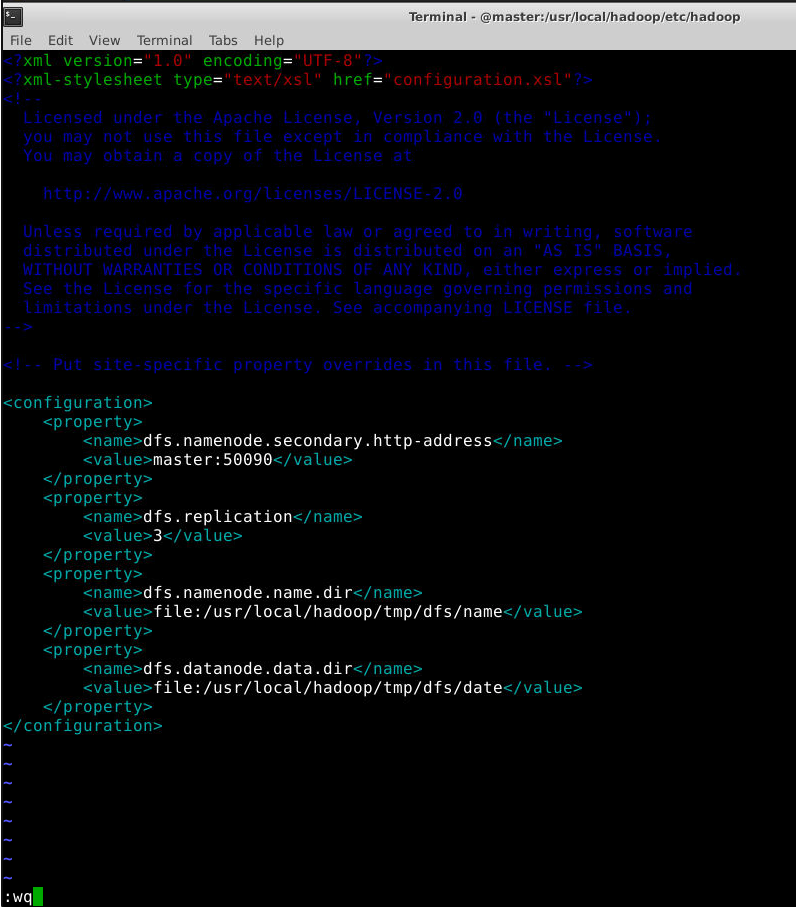
对于Hadoop的分布式文件系统HDFS而言,一般是采用冗余存储,冗余因子一般是3,也就是说一份数据保存3份副本。设置该冗余因子的参数为dfs.replication。所以,dfs.replication设置为3,文件具体内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/date</value>
</property>
</configuration>
3.4 修改文件mapred-site.xml
/usr/local/hadoop/etc/hadoop 目录下有一个 mapred-site.xml.template文件,需要复制该文件为 mapred-site.xml:
1
cp mapred-site.xml.template mapred-site.xml
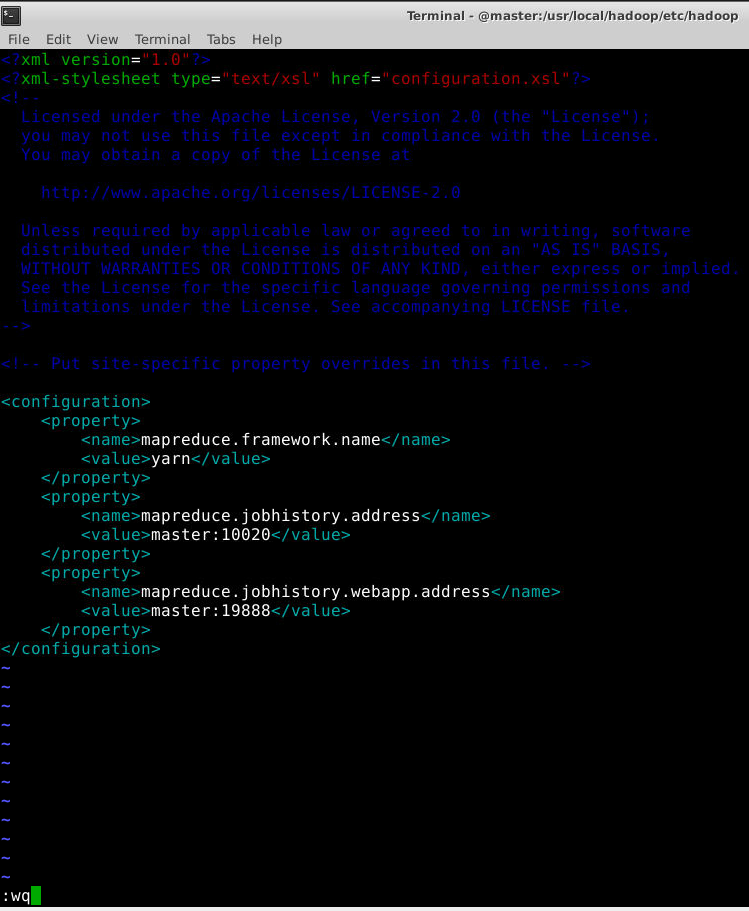
然后配置mapred-site.xml文件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
3.5 修改文件yarn-site.xml
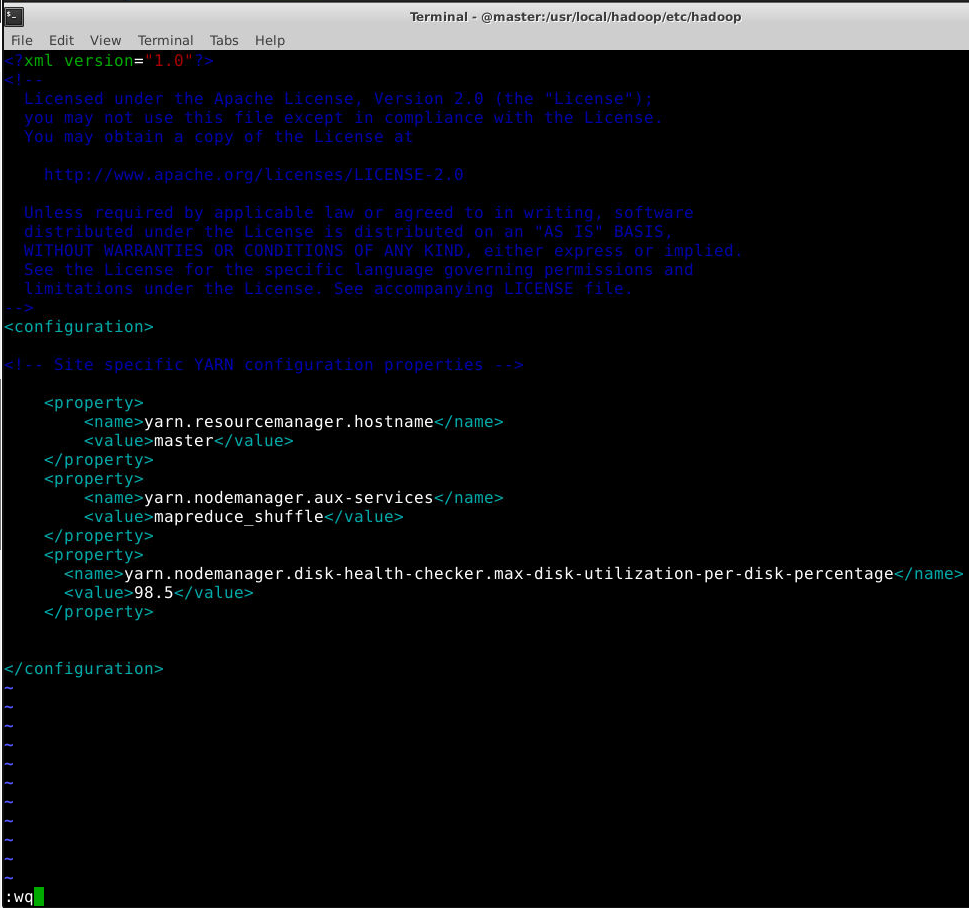
把 yarn-site.xml 配置为如下内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>98.5</value>
</property>
</configuration>
4 配置slave节点
五个配置文件配置完成之后,只需要把master节点上的 /usr/local/hadoop 文件复制到各个节点上即可。
在master节点上执行具体命令如下:
1
2
3
4
5
6
7
8
cd /usr/local
rm -rf ./hadoop/tmp
rm -rf ./hadoop/logs/*
tar -zcf ~/hadoop.master.tar.gz ./hadoop
cd ~
scp ./hadoop.master.tar.gz root@slave1:/root
scp ./hadoop.master.tar.gz root@slave2:/root
scp ./hadoop.master.tar.gz root@slave3:/root

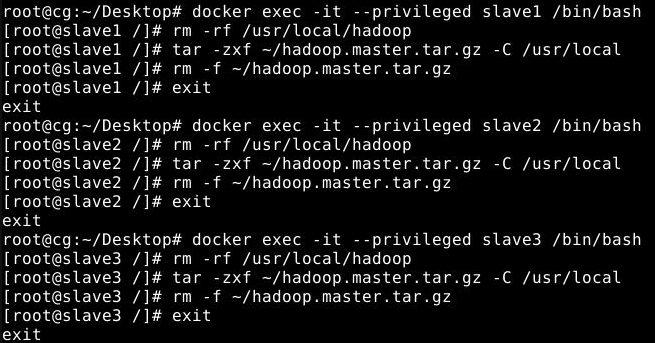
然后分别在slave1、slave2和slave3节点上执行如下命令:
1
2
3
rm -rf /usr/local/hadoop
tar -zxf ~/hadoop.master.tar.gz -C /usr/local
rm -f ~/hadoop.master.tar.gz
5 启动Hadoop集群
首次启动Hadoop集群时,需要先在master节点执行名称节点的格式化:
1
hdfs namenode -format
看见successfully formatted,即表示格式化成功。
现在可以启动Hadoop了,启动需要在master节点上进行,执行如下命令:
1
2
3
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
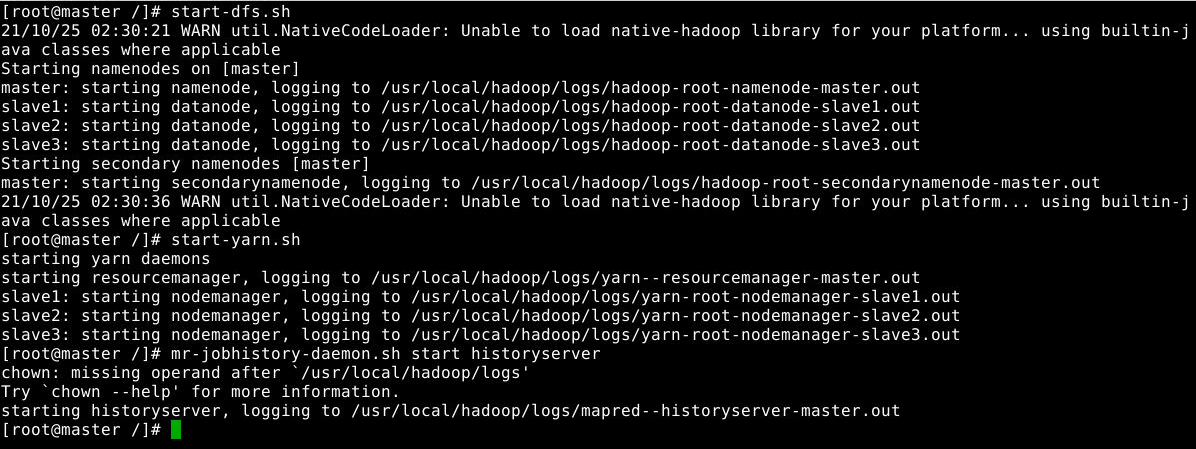
通过命令jps可以查看各个节点启动的进程。如果已经正确启动,则在master节点上可以看到如下进程:
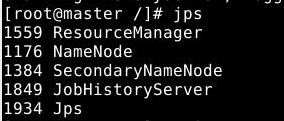
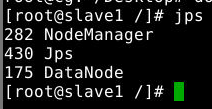
在slave节点上可以看到如下进程:
也可以在浏览器中输入 master的ip:50070 查看节点状态。
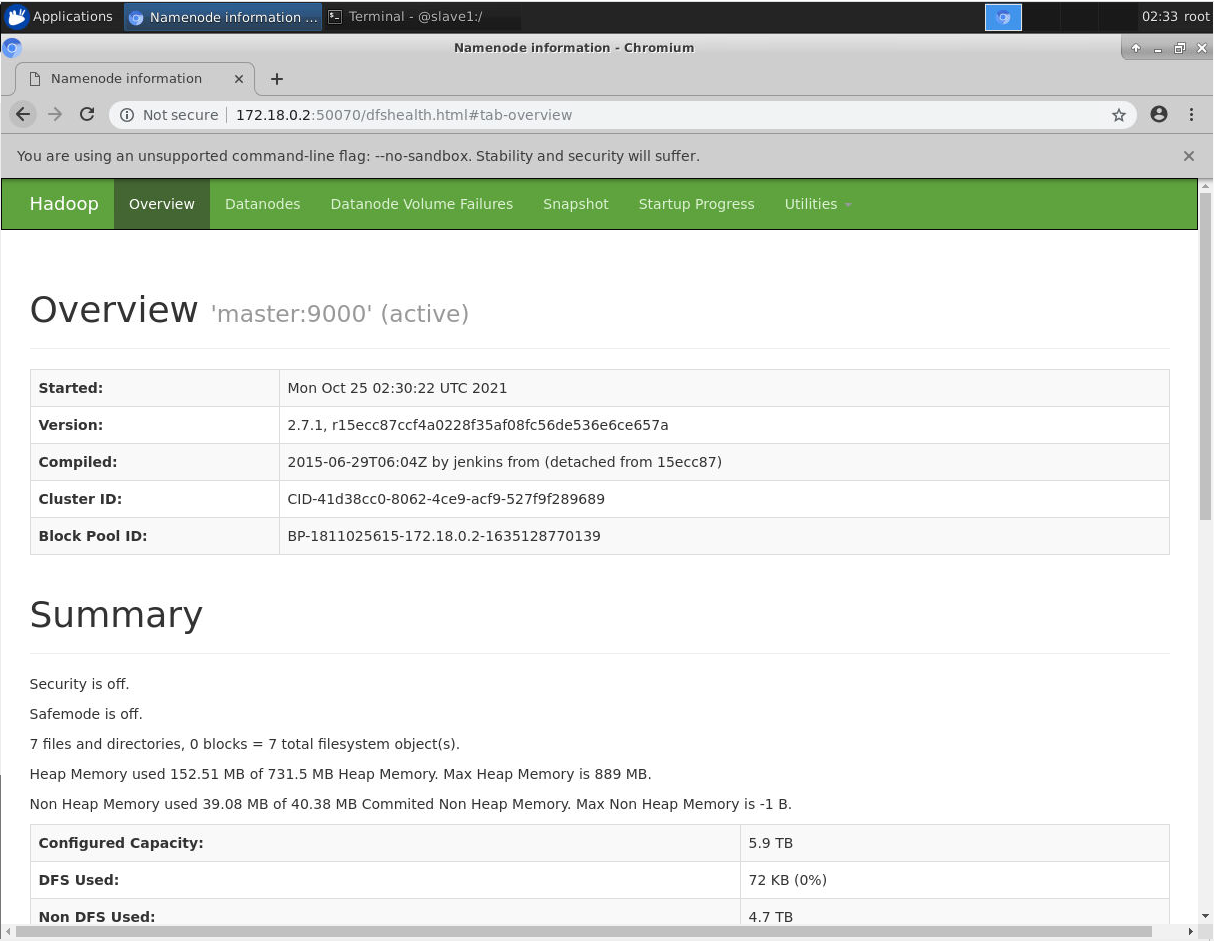
至此hadoop集群安装完成。