Hive实验二:Hive的复杂数据类型、内置函数与自定义函数
Hive的复杂数据类型、内置函数与自定义函数
1 实验准备
1.1 启动Hadoop集群
首先按照顺序启动四个Docker容器
1
2
3
4
docker start master
docker start slave1
docker start slave2
docker start slave3
接着使用以下命令,进入到master环境内:
1
docker exec -it --privileged master /bin/bash
然后在master容器内启动Hadoop服务
1
2
3
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
1.2 工作目录
本实验的工作目录为/course/hive/hive_type,在master节点上使用以下命令创建和初始化工作目录:
1
2
mkdir -p /course/hive/hive_type
cd /course/hive/hive_type
1.3 启动Hive
进入master节点
1
docker exec -it --privileged master /bin/bash
在master节点上输入如下命令启动 Hive服务 :
1
hive --service hiveserver2 &
接着在master节点上输入如下命令进入hive终端并连接Hive:
1
hive
输入账号/密码:root/root
这里因为版本的问题,会有一个报错,解决方案如下:
首先进入master节点:
1
docker exec -it --privileged master /bin/bash
接着吧/cgsrc/里的mysql-connector-java-5.1.40.tar.gz文件复制到/root/目录:
1
cp /cgsrc/mysql-connector-java-5.1.40.tar.gz /root
然后解压这个文件:
1
2
cd /root
tar -zxvf ./mysql-connector-java-5.1.40.tar.gz
最后把解压的架包复制到hive的lib目录,再启动hive即可:
1
2
3
4
cd mysql-connector-java-5.1.40
cp mysql-connector-java-5.1.40-bin.jar /usr/local/hive/lib/
hive
2 Array数据类型的使用
2.1 创建数据库表
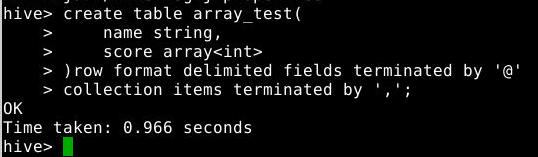
在hive console上执行如下命令创建表array_test:
1
2
3
4
5
create table array_test(
name string,
score array<int>
)row format delimited fields terminated by '@'
collection items terminated by ',';
注意:需要指明分隔符
2.2 导入数据
在桌面右键打开终端,使用如下命令进入master节点:
1
docker exec -it --privileged master bash
在目录/course/hive/hive_type下创建array_test.txt文件,并写入如下数据:
1
2
3
4
5
zhangshan@89,88,97,80
lisi@90,95,99,97
wangwu@90,77,88,79
zhaoliu@91,79,98,89
zhuba@89,99,98,90
在hive console上执行如下命令将master节点上的array_test.txt导入到表array_test中:
1
load data local inpath '/course/hive/hive_type/array_test.txt' into table array_test;

2.3 操作表
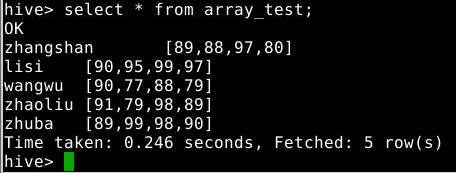
2.3.1 查询表
1
select * from array_test;
2.3.2 访问array类型的数据
array类型的数据可以通过’数组名[index]’的方式访问,index从0开始:查询表中array数据类型字段的指定列或满足条件的列
1
select score[1] from array_test where score[0]>90;

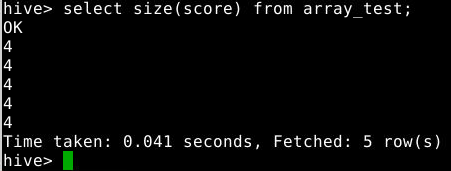
2.3.3 查询array数据类型字段的长度
1
select size(score) from array_test;
2.3.4 查看表结构
1
desc array_test;
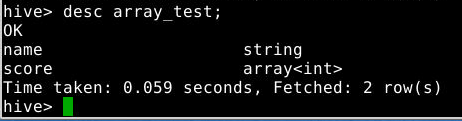
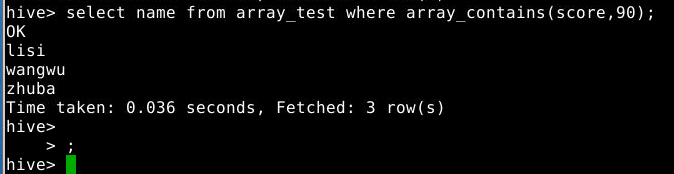
2.3.5 查询array中是否包含某个元素
array_contains():在字段类型为array中查找是否包含以及不包含某元素,在where后使用查询分数包含90分的学生的姓名
1
select name from array_test where array_contains(score,90);
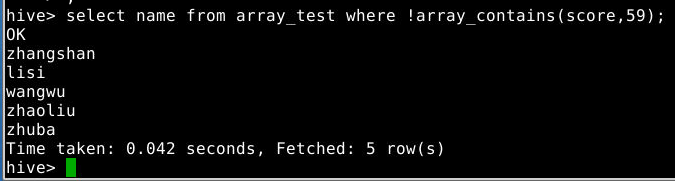
查询分数中不包含59分的学生的姓名
1
select name from array_test where !array_contains(score,59);
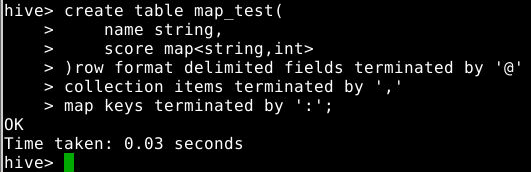
3 Map数据类型的使用
3.1 创建数据库
在hive console上执行如下命令创建表map_test:
1
2
3
4
5
6
create table map_test(
name string,
score map<string,int>
)row format delimited fields terminated by '@'
collection items terminated by ','
map keys terminated by ':';
注意:需要指明分隔符,以上命令将@设置为map元素间分隔符,:设置为key与value之间的分隔符
3.2 导入数据
在桌面右键打开终端,使用如下命令进入master节点:
1
docker exec -it --privileged master bash
在目录/course/hive/hive_type下创建map_test.txt文件,并写入如下数据:
1
2
3
4
zhangshan@math:90,english:89,java:88,hive:80
lisi@math:98,english:79,java:96,hive:92
wangwu@math:88,english:86,java:89,hive:88
zhaoliu@math:89,english:78,java:79,hive:77

在hive console上执行如下命令将master节点上的map_test.txt导入到表map_test中:
1
load data local inpath '/course/hive/hive_type/map_test.txt' into table map_test;

3.3 操作表
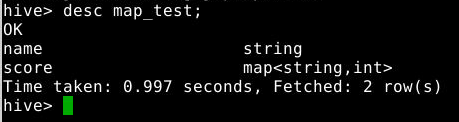
3.3.1 查询表结构
1
desc map_test;
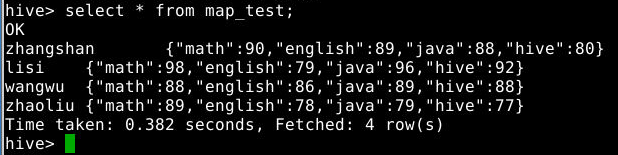
3.3.2 查询表中所有信息
1
select * from map_test;
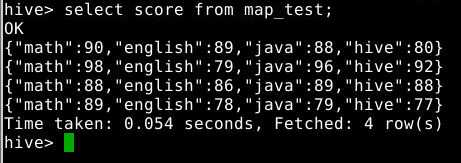
3.3.3 查询map中所有信息
1
select score from map_test;
3.3.4 查询name为lisi的所有成绩信息
1
select score from map_test where name='lisi';

3.3.5 查询name为lisi的所有成绩,并用UDTF把结果变成多行
1
select explode(score) from map_test where name='lisi';
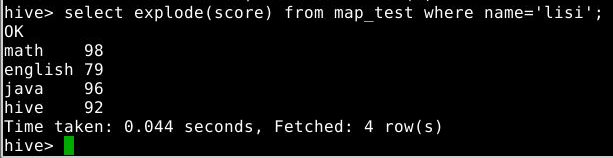
注意:Explode单独使用只能单个字段,如果要和别的字段一起使用必须使用lateral view explode,否则报错

Lateral View语法将值展开为一个新的虚拟表
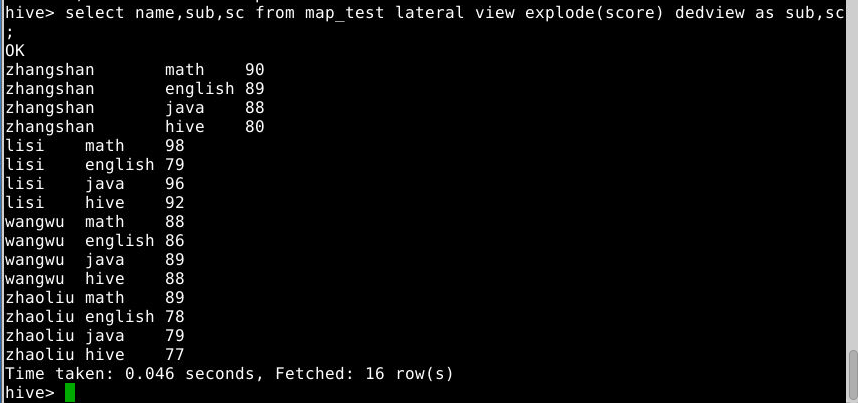
3.3.6 使用下标访问map:查询所有学员的数学成绩
1
select name,score['math'] from map_test;
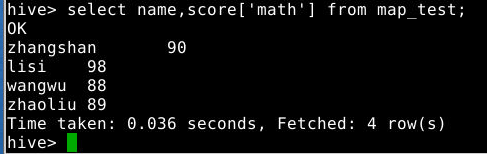
3.3.7 使用if判断结果
1
select name,if(score['math']>=90,'pass','fail') from map_test;
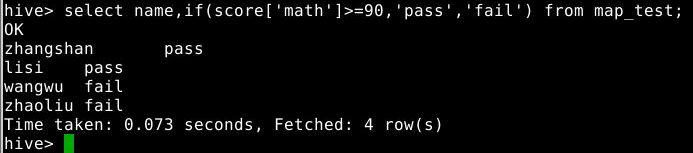
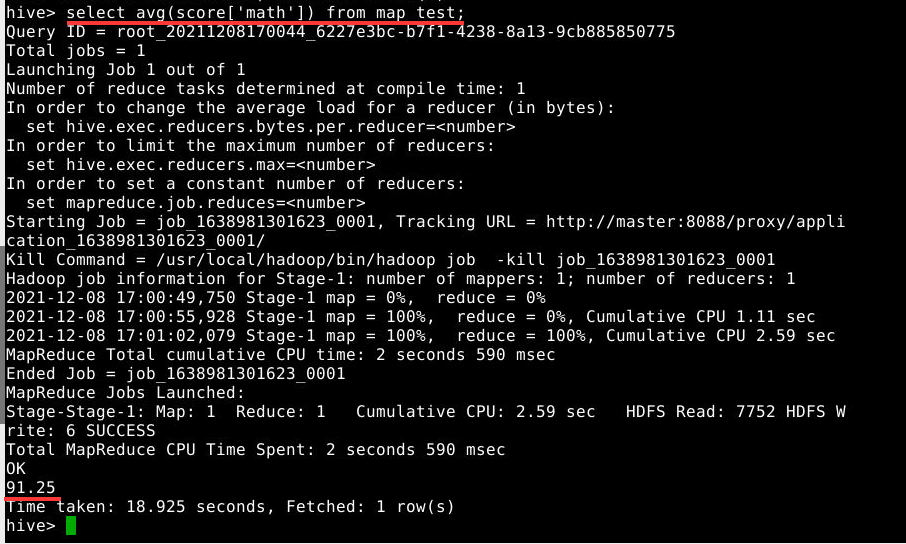
3.3.8 求所有学员数学成绩的平均分
1
select avg(score['math']) from map_test;
3.3.9 map_values(map字段名):取map字段的全部value值
1
select name,map_values(score) from map_test;
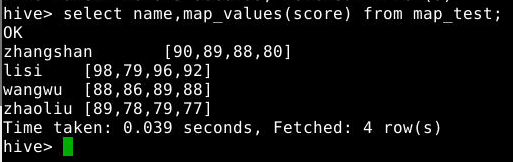
3.3.10 size()查看map长度即有多少键值对
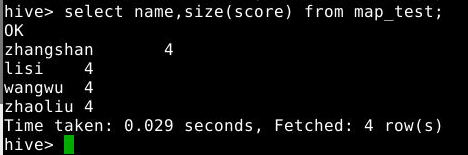
1
select name,size(score) from map_test;
4 Struct数据类型的使用
4.1 创建数据库表
在hive console上执行如下命令创建表struct_test:
1
2
3
4
5
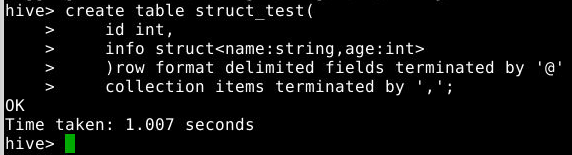
create table struct_test(
id int,
info struct<name:string,age:int>
)row format delimited fields terminated by '@'
collection items terminated by ',';
注意:需要指明分隔符
4.2 导入数据
在桌面右键打开终端,使用如下命令进入master节点:
1
docker exec -it --privileged master bash
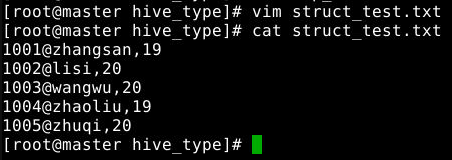
在目录/course/hive/hive_type下创建struct_test.txt文件,并写入如下数据:
1
2
3
4
5
1001@zhangsan,19
1002@lisi,20
1003@wangwu,20
1004@zhaoliu,19
1005@zhuqi,20
在hive console上执行如下命令将master节点上的struct_test.txt导入到表struct_test中:
1
load data local inpath '/course/hive/hive_type/struct_test.txt' into table struct_test;

4.3 操作表
4.3.1 查看表结构
1
desc struct_test;
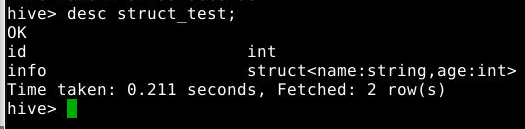
4.3.2 查看表的内容
1
select * from struct_test;
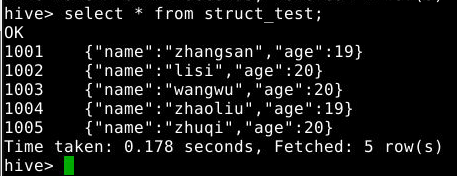
4.3.3 struct类型的字段通过“字段名.成员名”访问具体每一项。
1
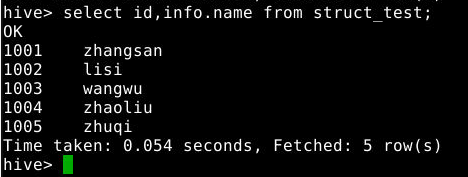
select id,info.name from struct_test;
5 hive的函数
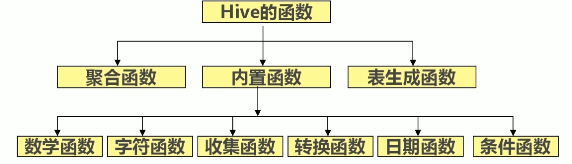
- 内置函数:可以直接调用
- 自定义函数:写java程序,在hive中自定义函数
5.1 内置函数的使用
5.1.1 查询函数相关信息的命令
- 查看内置函数:
show functions; - 查看内置函数的描述信息:
desc function 函数名; - 查看函数的详细信息:
desc function extended 函数名;
5.1.2 常用数学函数:
roundceil:向上取整floor:向下取整
5.1.3 常用字符函数
lower:字符串转成小写upper:字符串转成大写length:字符串的长度concat:拼接字符串substr:求字符串的子串substr(a,b):从a中第b位开始,取右边所有的字符substr(a,b,c):从a中第6位开始,取右边c个字符trim:去掉左右空格lpad:左填充rpad:右填充
5.1.4 hive的收集函数
size(map集合):返回map集合中键值对的个数
1
select size(map("name","zhang","age",21,"sex","boy"));
注意map中参数间逗号间隔
- size(array集合)
5.1.5 hive的类型转换函数
castselect cast(1 as float);
5.1.6 hive的日期函数
to_date:取出字符串中日期部分yearmonthdayweekofyeardatediffdate_adddate_sub
5.1.7 条件函数
coalesce:从左到右返回第一个不为null的值1
select examscore,exscore,ptscore,coalesce(examscore,exscore,ptscore) from score limit 5;
case...when...:条件表达式,在hql语句中实现if-else逻辑 语法:case a when b then c [when d then e] * [else f] endex:显示score表中男生卷面分增加2分,女生卷面分增加5分后的各个学生的分数信息1
select name,sex,examscore,case sex when '男' then examscore+2 else examscore+5 end from score;
5.1.8 聚合函数
countsumminmaxavg
eg:统计score中所有列的记录数,卷面分的平均值
1
select count(*),avg(examscore) from score;
5.1.9 表生成函数
explode:把map中的每个元素的键值对或array中的元素单独生成一个行
5.2 hive自定义函数UDF
可以直接引用于select语句,对查询结果做格式化处理后,再输出内容。
5.2.1 自定义函数UDF
自定义函数UDF需要继承org.apache.hadoop.hive.ql.exec.UDF,步骤如下:
5.2.1.1 建工程
(1)在桌面右键打开新的终端,执行命令eclipse &打开eclipse IDE.
(2)启动eclipse后workspace选择/headless/course/hive文件夹
(3)在eclipse中依次点击:File->New->Project->Java Project->Next。
(4)在项目名称(Project Name)处填入MyUDF,将工程位置设置为文件夹~/course/hive/MyUDF,点击Finish。
5.2.1.2 导入依赖包:hive的lib中的jar包
在MyUDF项目上右键->New->Folder,填入lib,点击Finish。
将master节点下的/usr/local/hive/bin/hive/lib下的所有jar包,拷贝到项目的lib文件夹下。
1
2
cd /usr/local/hive/lib
cp ./*.jar /course/hive/MyUDF/lib/
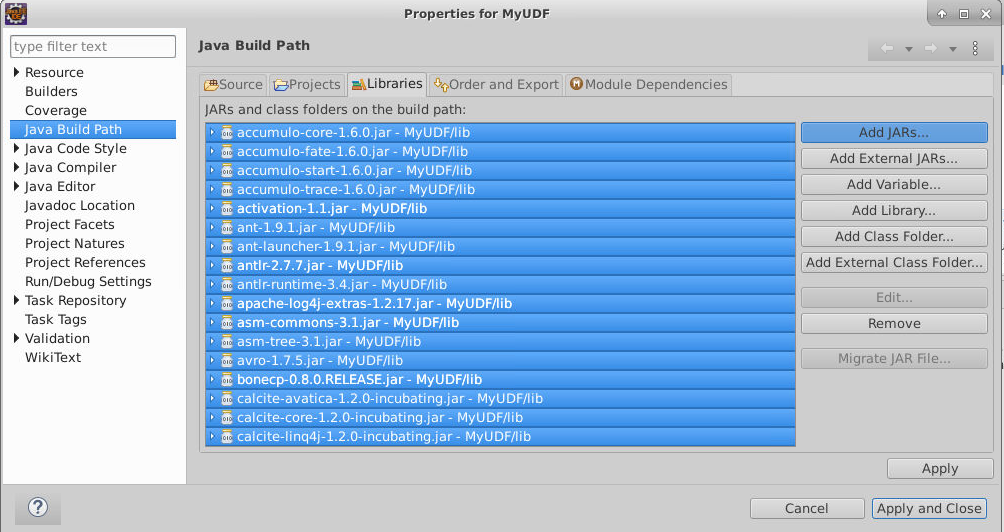
在lib文件夹上右键->Build Path->Configure Build Path:
点击Libraries选项卡,点击Add JARS,选中lib文件夹下的所有新添加的jar包:
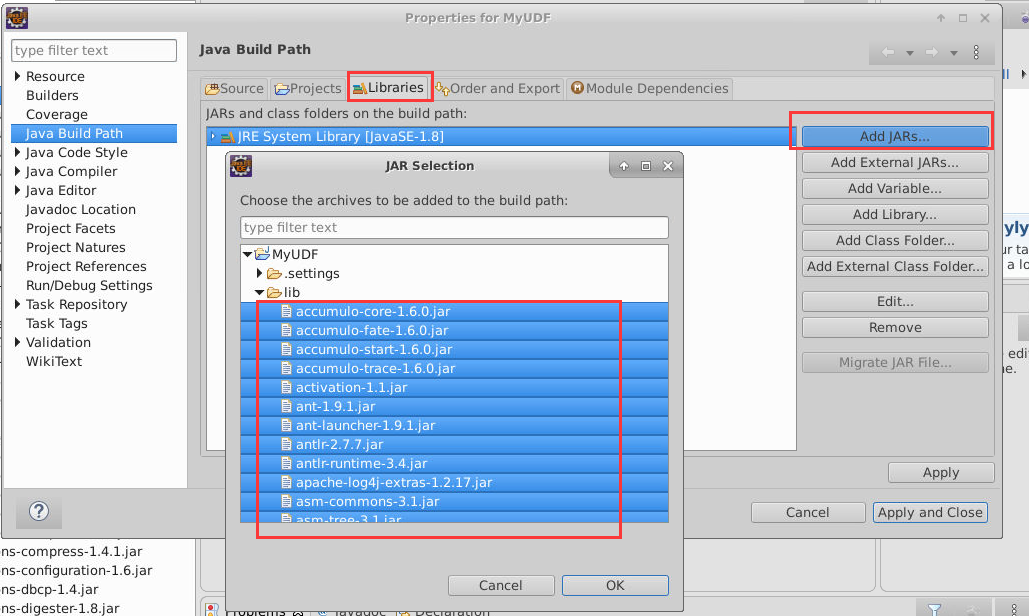
点击OK->Apply and Close,完成hbase库的导入。
5.2.1.3 定义一个类,继承UDF,实现一个或多个public类型evaluate方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
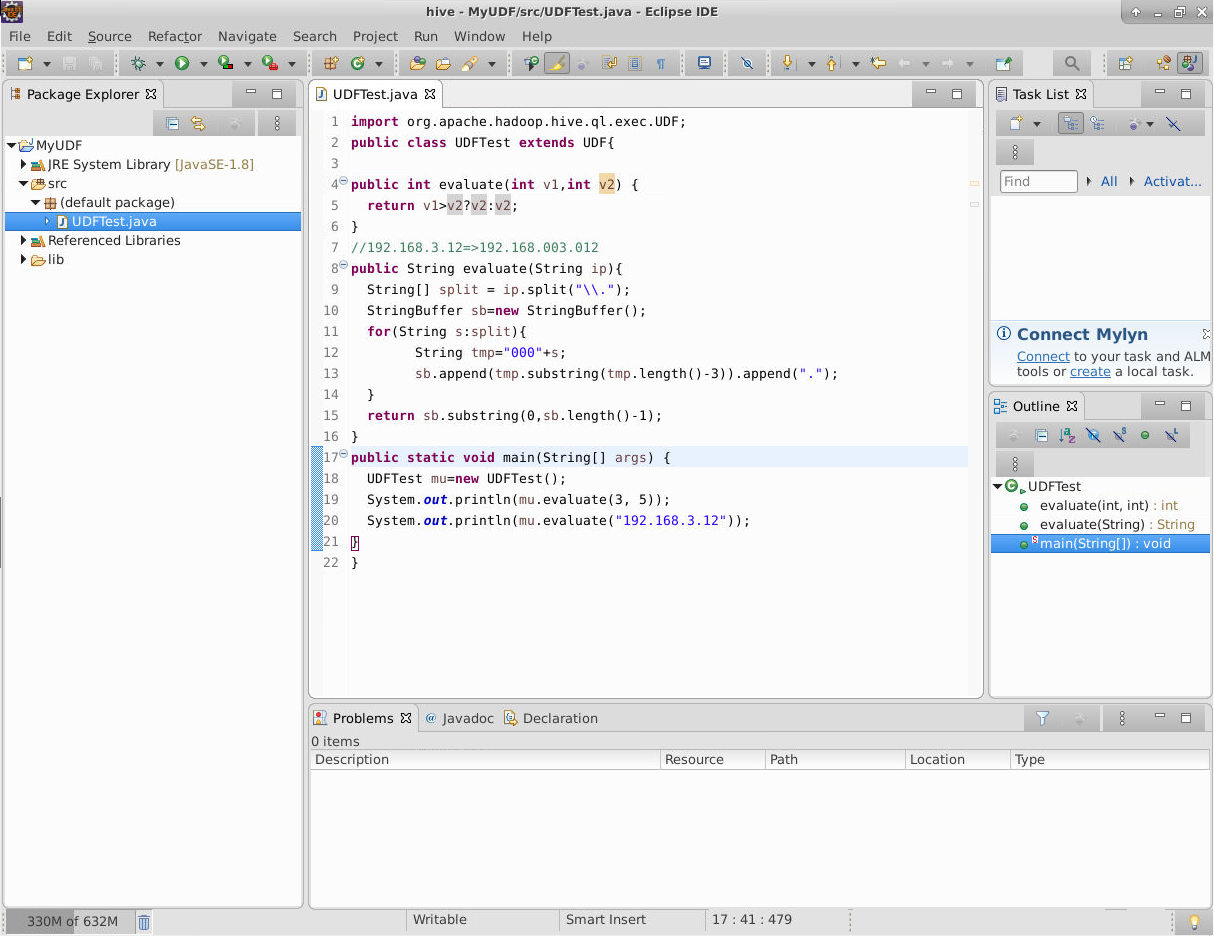
import org.apache.hadoop.hive.ql.exec.UDF;
public class UDFTest extends UDF{
//实现一个或多个evaluate方法
/*
* 参数代表需要处理的字段,需要同时处理两个字段,传两个参数,参数的类型跟字段的类型匹配
* 一般至少传入一个参数
* 返回值:代表的是最终处理的结果
* 例如:两个值的较大值
*/
public int evaluate(int v1,int v2) {
return v1>v2?v2:v2;
}
//192.168.3.12=>192.168.003.012
public String evaluate(String ip){
String[] split = ip.split("\\.");
StringBuffer sb=new StringBuffer();
for(String s:split){
String tmp="000"+s;
sb.append(tmp.substring(tmp.length()-3)).append(".");
}
return sb.substring(0,sb.length()-1);
}
public static void main(String[] args) {
UDFTest mu=new UDFTest();
System.out.println(mu.evaluate(3, 5));
System.out.println(mu.evaluate("192.168.3.12"));
}
}
5.2.2 使用
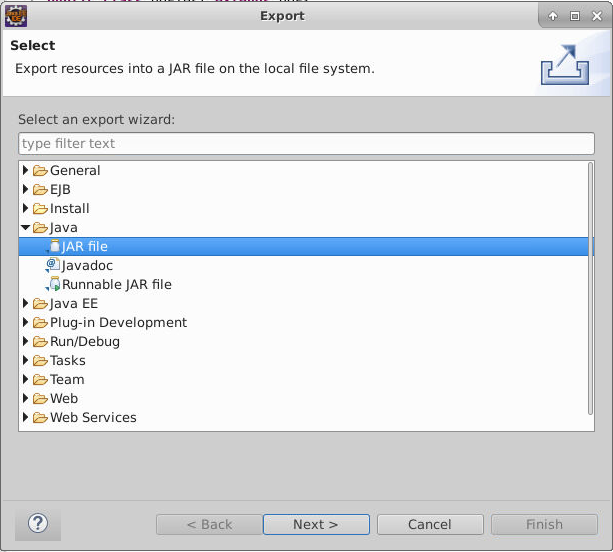
在MyUDF项目上右键->New->Folder,填入target,点击Finish。
在MyUDF项目上,点击右键选择Export->Java->JAR file->next,如下图所示:
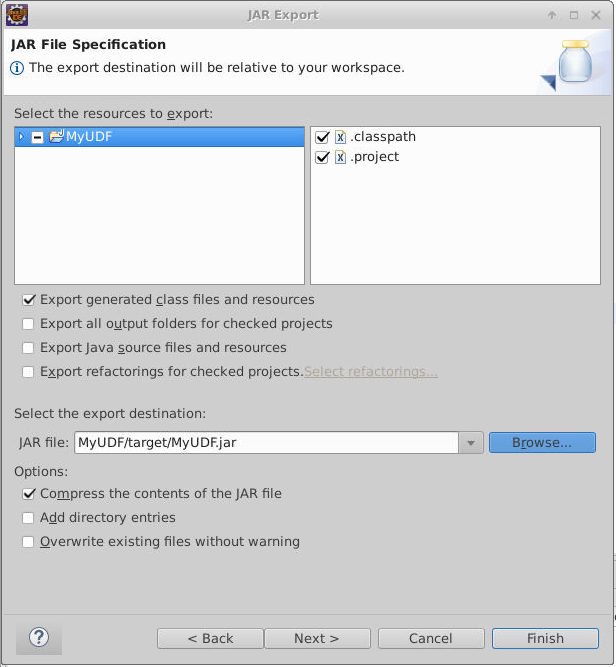
jar包名称设置为MyUDF.jar并设置将jar包保存在当前项目的target目录下:
设置Main Class:
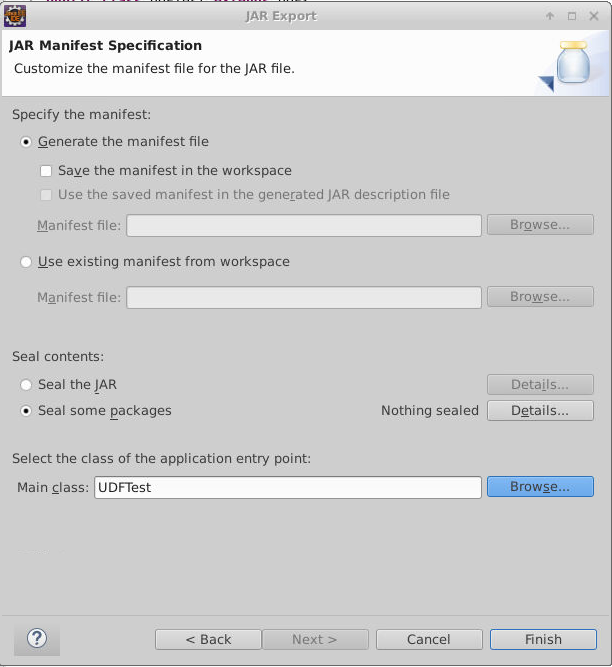
点击Finish完成jar包导出。
桌面右键打开终端,执行如下命令进入master节点,并切换到target目录:
1
2
docker exec -it --privileged master /bin/bash
cd /course/hive/MyUDF/target
在master节点上执行如下命令到hive的客户端,并添加jar包:
1
2
hive
add jar /course/hive/MyUDF/target/MyUDF.jar;
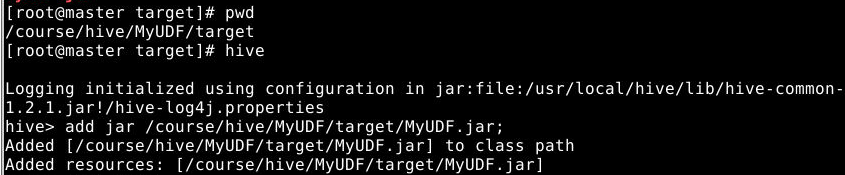
检测jar包是否添加成功:
1
list jars;

给自定义函数添加别名,并且在hive中注册这个函数:
1
create temporary function my as 'UDFTest';

my是自定义函数的别名
然后查看hive的函数库汇总有没有添加的自定义函数:
1
show functions;
通过自定义的函数名字和参数来确定调用的是哪一个evaluate方法
1
2
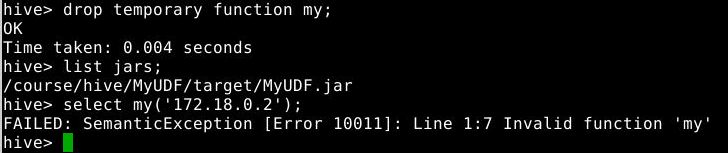
select my('172.18.0.2');
select my(12,43);
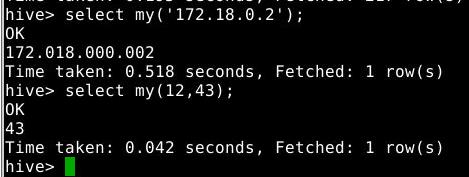
5.2.3 注意
这种方式创建的是临时函数,当前客户端关闭即没有了,需要重新执行在hive中添加jar包的步骤。生产中也是这种方式。
同一个udf函数,打了多个jar包,加载多次,只有第一次生效。
销毁创建的临时函数:
1
drop temporary function <函数名>;
5.2.4 创建永久函数
创建如下函数并打成jar包,jar包名:
DateToString.jarTips: 可以直接在已有的
MyUDF项目的src目录下创建DateToString类,导出时,在DateToString.class文件上右键选择Export进行导出1 2 3 4 5 6 7 8 9 10 11 12 13
import java.text.SimpleDateFormat; import java.util.Date; import org.apache.hadoop.hive.ql.exec.UDF; public class DateToString extends UDF{ public String evaluate(long number){ long num=number; SimpleDateFormat dfs=new SimpleDateFormat("yyyy-MM-dd"); return dfs.format(new Date(num)); } public static void main(String[] args) { System.out.print(new DateToString().evaluate(1527639535750l)); } }
将jar包上传至hdfs中的
/course/hive/udf目录下(如果hdfs没有该目录则先创建该目录)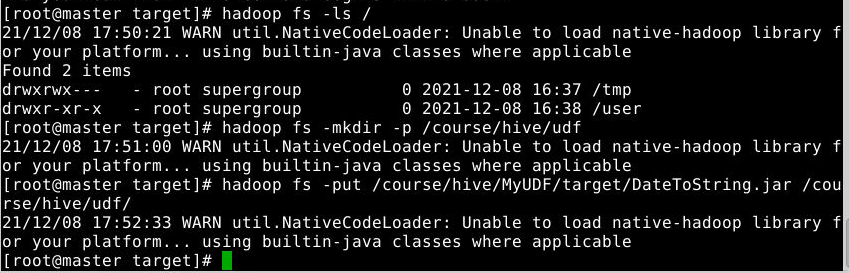
执行:
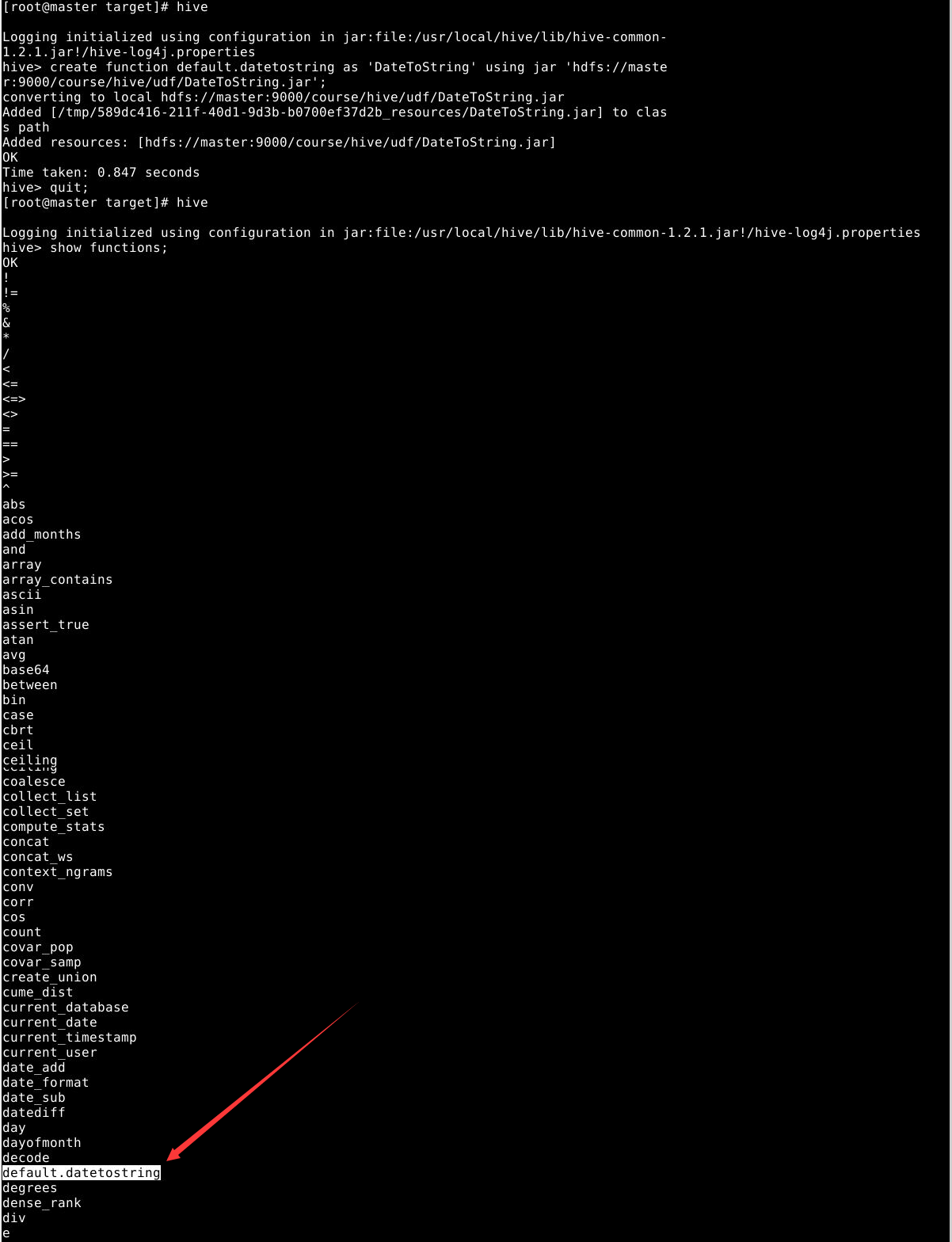
1
create function default.datetostring as 'DateToString' using jar 'hdfs://master:9000/course/hive/udf/DateToString.jar';
关闭客户端再打开hive console观察该函数